
Вышел MSEB — новый бенчмарк для оценки интеллекта звуковых моделей
Звуковой ИИ — это не просто транскрибация речи, а комплексное понимание аудиосигналов, от шумов улицы до птичьего щебета. Когда модели ИИ борются за универсальность, фрагментированные подходы только тормозят прогресс, и вот появляется инструмент, который меняет игру.
По сообщению Google Research, новый бенчмарк под названием Massive Sound Embedding Benchmark (MSEB) унифицирует восемь ключевых способностей звуковых моделей: от поиска и классификации до реконструкции. Это открытая платформа, представленная на NeurIPS 2025, которая позволяет сравнивать модели на основе реальных сценариев и выявлять пробелы в текущих подходах.
Звук критичен для мультимодального восприятия, где системы — будь то голосовые помощники или автономные агенты — должны обрабатывать аудио наравне с текстом или изображениями. MSEB тестирует модели на трансформацию сырого звука в эмбеддинги, полезные для множества задач.
Три основы MSEB: единый каркас
Бенчмарк строится на трех столпах, давая сообществу инструменты для создания моделей следующего поколения.
Разнообразные датасеты для реальных ситуаций
Качество данных определяет успех. MSEB включает набор доступных датасетов, отражающих глобальное разнообразие. Центральный — Simple Voice Questions (SVQ), с 177 352 короткими речевыми запросами на 26 языках и 17 локалях. Записи сделаны в четырех акустических условиях: чистый звук, фоновый шум, уличный трафик и медиа-шум, с метаданными о говорящих и ключевых терминах. Доступен на Hugging Face.
Также интегрированы публичные датасеты:
- Speech-MASSIVE: для понимания мультиязыковой речи и классификации намерений.
- FSD50K: большой набор для распознавания 200 классов звуковых событий из AudioSet Ontology.
- BirdSet: масшабный бенчмарк для биоакустики птиц, включая сложные звуковые ландшафты.
Команда активно расширяет MSEB новыми датасетами и приглашает сообщество к сотрудничеству через GitHub.
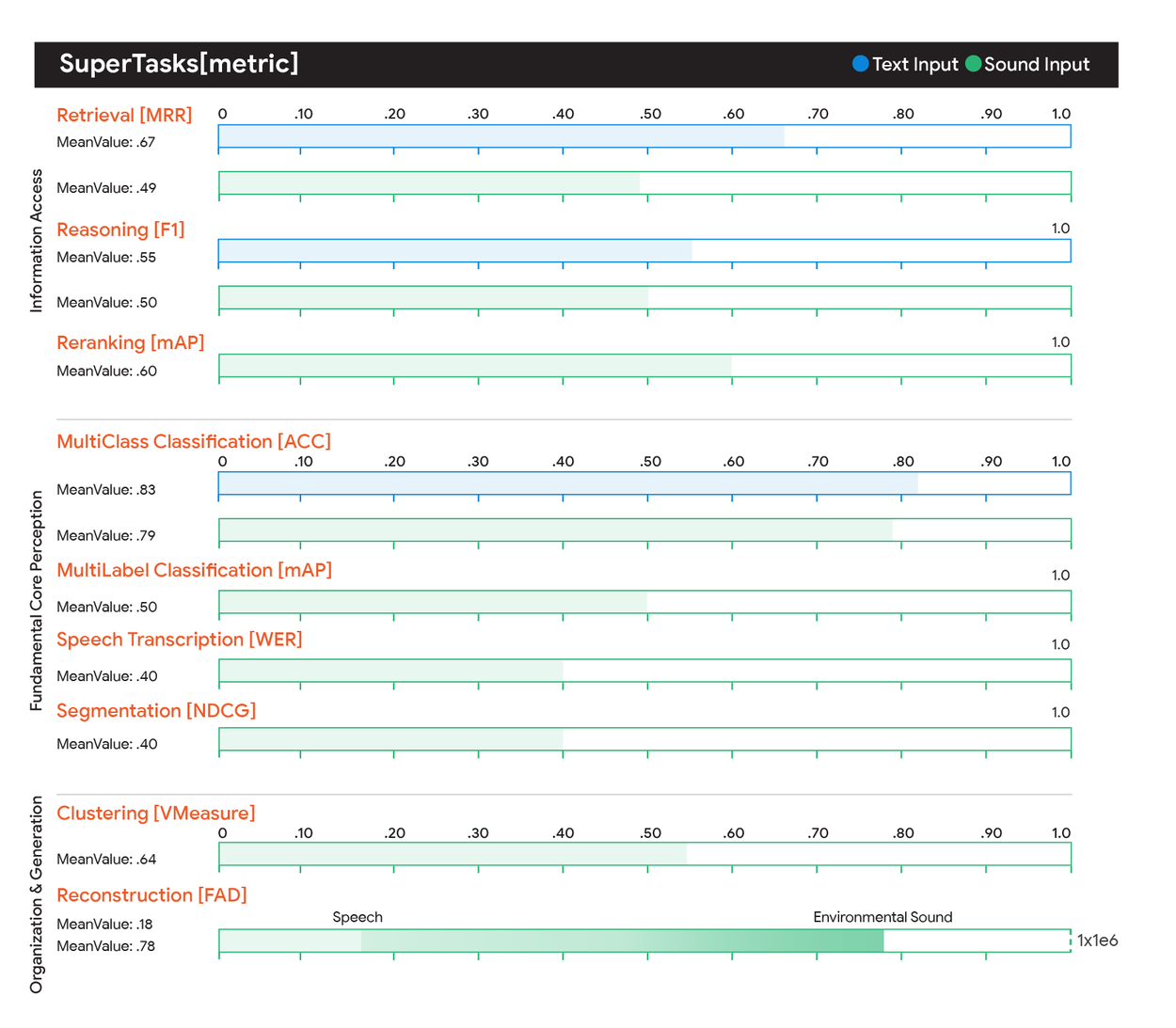
Восемь ключевых способностей
Дизайн MSEB предполагает мультимодальность: каждая задача использует звук как вход, но сочетает с текстом или знаниями для реализма.
Восемь супер-задач:
- Поиск (голосовой поиск): нахождение релевантных документов по речевому запросу.
- Рассуждение (умные ассистенты): точный ответ в документе на основе вопроса.
- Классификация (мониторинг/безопасность): категоризация по атрибутам говорящего, намерениям или событиям.
- Транскрибация: преобразование аудио в текст (ASR).
- Сегментация (индексация): выделение ключевых терминов с временными метками.
- Кластеризация (организация): группировка звуков по общим чертам без меток.
- Переранжировка (уточнение гипотез): улучшение списка текстовых предположений (например, из ASR).
- Реконструкция (генеративный ИИ): качество эмбеддинга по восстановлению волновой формы.
Источник: research.google
Задачи охватывают от доступа к информации до восприятия и генерации, с фокусом на практические мультимодальные применения, включая музыку или комбинации с изображениями.
Надежный каркас оценки и базовые уровни
Главная цель — установить эталон и показать запас для улучшения. Оценка делится на:
- Семантические (поиск, рассуждение): понимание смысла даже в шуме.
- Акустические (классификация, кластеризация): идентификация говорящего или звуков независимо от смысла.
Каркас независим от модели, тестируя от каскадных систем до end-to-end кодировщиков.
Методология сравнения
MSEB сравнивает модели с эталонными текстами для семантических задач и лучшими специализированными решениями для других. Эксперименты показывают, что текущие эмбеддинги далеки от универсальности, с значительным потенциалом роста.
Представьте, что ваши аудиомодели шепотом признаются: «Мы не слышим разницы между криком чайки и мотором лодки». MSEB — это не просто тест, а зеркало, где отражаются провалы в универсальности, и пока гиганты гонятся за мультимодальностью, этот бенчмарк напоминает, что истинный интеллект не в скорости, а в глубине понимания. Шутка ли, когда модель путает птичью песнь с сиреной — а мы все еще называем это прогрессом.
Источник новости: Google Research.




