
Verbatim RAG: метод извлечения текста для полного устранения галлюцинаций в RAG-системах
Новый подход к построению RAG-систем обещает полностью устранить проблему галлюцинаций языковых моделей. Вместо генерации ответов на основе извлеченных документов, система Verbatim RAG заставляет модели выбирать точные фрагменты текста, которые непосредственно отвечают на вопрос пользователя.
Извлечение вместо генерации
Фундаментальная проблема традиционных RAG-систем заключается в том, что языковые модели генерируют текст вероятностным образом. Даже при наличии идеального контекста модель выбирает токены из вероятностного распределения, что неизбежно приводит к аппроксимациям, перефразированию и фактическим ошибкам.
Эта проблема усугубляется в современных агентских RAG-системах. Когда один запрос запускает 7-8 последовательных вызовов языковой модели (планирование, извлечение, синтез, проверка и т.д.), каждый со своей вероятностью галлюцинаций, совокупная частота ошибок становится значительной. Если каждый вызов имеет 10%-ную вероятность внесения ошибки, то 8-шаговый агентский рабочий процесс имеет примерно 60%-ную вероятность содержать хотя бы одну галлюцинацию.
Verbatim RAG использует другой подход: вместо того чтобы просить языковую модель генерировать ответ на основе извлеченных документов, система ограничивает её извлечением точных фрагментов текста, которые отвечают на вопрос. Эти фрагменты затем компонуются в ответ без какого-либо генеративного переписывания.
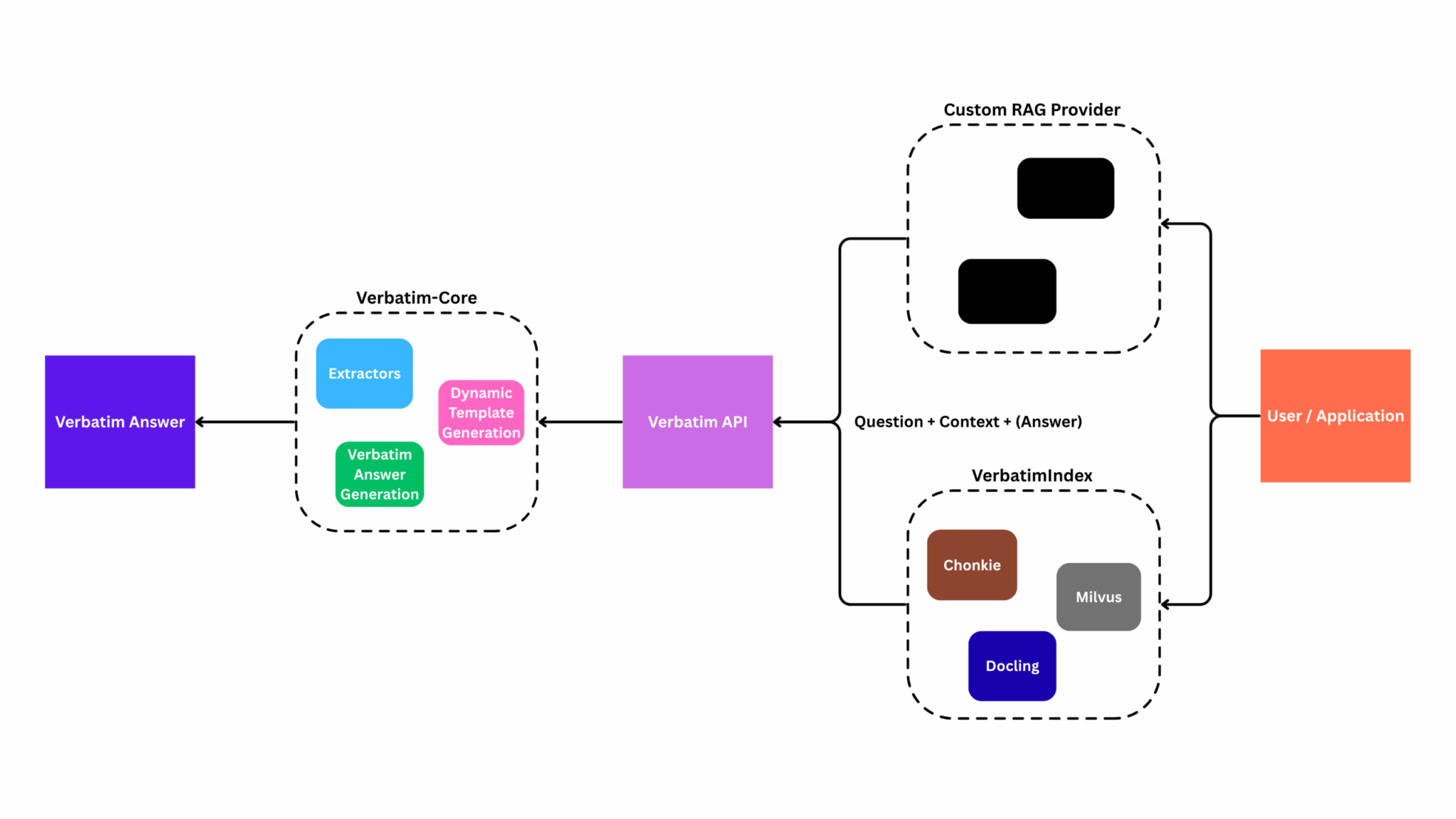
Почему это работает: Извлечение — это задача классификации (отвечает ли этот фрагмент на вопрос?), а не задача генерации. Модель никогда не производит новые токены, которые аппроксимируют исходный контекст, она только определяет, какие существующие токены следует включить. Это устраняет проблему вероятностной генерации, вызывающей галлюцинации.
Результат: каждое число, каждый факт, каждое утверждение в ответе напрямую отслеживается до исходного текста.
Быстрый старт: ноль галлюцинаций за 15 строк кода
Установите необходимые зависимости:
!pip install verbatim-rag
Затем создайте систему Verbatim RAG:
from verbatim_rag import VerbatimRAG, VerbatimIndex
from verbatim_rag.vector_stores import LocalMilvusStore
from verbatim_rag.embedding_providers import SpladeProvider
from verbatim_rag.schema import DocumentSchema
# 1. Создание индекса (уровень хранения) - работает на CPU!
store = LocalMilvusStore("./demo.db", enable_sparse=True, enable_dense=False)
embedder = SpladeProvider("opensearch-project/opensearch-neural-sparse-encoding-doc-v2-distill", device="cpu")
index = VerbatimIndex(vector_store=store, sparse_provider=embedder)
# 2. Добавление документа
doc = DocumentSchema(
content="""
# Methods
We used two approaches: zero-shot LLM extraction and a fine-tuned ModernBERT classifier on 58k synthetic examples.
# Results
The system achieved 42.01% accuracy on ArchEHR-QA.
""",
title="Research Paper"
)
index.add_documents([doc])
# 3. Создание RAG с предотвращением галлюцинаций
rag = VerbatimRAG(index, model="gpt-4o-mini")
# 4. Получение точных цитат, а не галлюцинаций
response = rag.query("What approaches were used?")
print(response.answer)
# [1] We used two approaches: zero-shot LLM extraction and a fine-tuned ModernBERT classifier on 58k synthetic examples.
Примечание: Используйте плотные эмбеддинги (SentenceTransformers, OpenAI) или гибридный поиск, заменив поставщика эмбеддингов. Подробности см. в документации.
Уже есть RAG-система? Оберните её в 15 строк
Ключевой паттерн интеграции: оберните существующее извлечение LangChain/LlamaIndex с помощью слоя извлечения Verbatim. Ваш конвейер индексирования остается неизменным, вы только добавляете шаг извлечения поверх существующего извлечения.
Установите необходимые зависимости:
!pip install langchain langchain-openai langchain-community openai faiss-cpu langchain-text-splitters
Затем оберните существующую систему LangChain RAG:
from verbatim_rag.providers import RAGProvider
from verbatim_rag import verbatim_query
# Ваша существующая настройка LangChain
from langchain_community.embeddings import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.documents import Document
from typing import List, Dict, Any, Optional
# 1. Создание примеров документов
docs = [
Document(
page_content="""
# Methods
We used two approaches: zero-shot LLM extraction and a fine-tuned ModernBERT classifier on 58k synthetic examples.
# Results
The system achieved 42.01% accuracy on ArchEHR-QA.
""",
metadata={"title": "Research Paper 1", "source": "paper1.pdf", "year": 2025},
)
]
# 2. Индексирование с LangChain (ваша существующая настройка)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=50)
splits = text_splitter.split_documents(docs)
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(splits, embeddings)
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
# 3. Обертка вашего LangChain ретривера
class LangChainRAGProvider(RAGProvider):
def __init__(self, langchain_retriever):
self.retriever = langchain_retriever
def retrieve(
self, question: str, k: int = 5, filter: Optional[str] = None
) -> List[Dict[str, Any]]:
# Использование извлечения LangChain
docs = self.retriever.invoke(question)
# Конвертация в формат Verbatim
context = []
for doc in docs[:k]:
context.append(
{
"content": doc.page_content,
"title": doc.metadata.get("title", ""),
"source": doc.metadata.get("source", ""),
"metadata": doc.metadata,
}
)
return context
# 4. Использование Verbatim с вашей существующей LangChain RAG
provider = LangChainRAGProvider(retriever)
response = verbatim_query(provider, "What methods were used?", k=5)
print(response.answer)
# Output: [1] We used two approaches: zero-shot LLM extraction and a fine-tuned ModernBERT classifier on 58k synthetic examples.
Этот подход сохраняет вашу существующую систему извлечения (эмбеддинги, векторное хранилище, стратегию чанкинга), добавляя при этом извлечение точных фрагментов текста. Единственное изменение происходит на финальном этапе генерации ответа.
Почему это важно
Даже при идеальном извлечении шаг генерации вносит галлюцинации. Рассмотрим этот пример:
| Традиционный RAG | Verbatim RAG | |
|---|---|---|
| Вопрос | «Сколько синтетических данных?» | «Сколько синтетических данных?» |
| Извлечено | «Мы создали 60k примеров» | «Мы создали 60k примеров» |
| Сгенерировано | «Около 58,000 примеров» | « Мы создали 60k примеров» |
Языковая модель аппроксимировала «60k» до «58,000» во время генерации токенов — не потому что извлечение не удалось, а потому что модель выбирает из изученного распределения по приблизительным формулировкам.
Это происходит потому что:
- Генерация на уровне токенов не сохраняет точные числовые значения из контекста
- Цель предсказания токенов изучает вероятностные распределения по перефразировкам, а не механизмы точного копирования
- Авторегрессивная выборка может отклоняться от исходного текста даже при высоком внимании к контексту
Традиционные RAG-системы пытаются смягчить это через улучшенные промпты, извлечение или повторное ранжирование. Но это не решает коренную причину: модель генерирует новые токены вместо выбора существующих.
# Традиционный RAG: Модель генерирует токены (вероятностно) answer = "They generated approximately 58,000 synthetic training samples" # Verbatim RAG: Модель выбирает фрагменты (детерминированно при извлечении) answer = "[1] We created 60k examples."
Подход Verbatim RAG — это долгожданное решение фундаментальной проблемы RAG-систем. Вместо бесконечной игры в кошки-мышки с промпт-инжинирингом, разработчики получают работающий метод устранения галлюцинаций на архитектурном уровне. Особенно впечатляет возможность интеграции с существующими системами — это не очередной фреймворк, который нужно внедрять с нуля, а надстройка над уже работающими решениями. Правда, возникает вопрос: не потеряем ли мы в качестве ответов, если полностью запретим модели перефразировать и структурировать информацию?
По материалам HuggingFace.




