
Тестирование GPT-OSS моделей OpenAI: меньшая модель оказалась эффективнее
После шестилетнего перерыва OpenAI выпустила две открытые языковые модели: gpt-oss-120b и gpt-oss-20b. Компания DataRobot провела комплексное тестирование этих моделей с помощью своего фреймворка оптимизации рабочих процессов syftr, включая поддержку новой функции OpenAI — «уровня мышления».
Методология тестирования
Исследователи сравнили модели GPT-OSS с другими сильными открытыми моделями:
- qwen3-235b-a22b
- glm-4.5-air
- nemotron-super-49b
- qwen3-30b-a3b
- gemma3-27b-it
- phi-4-multimodal-instruct
Каждая модель GPT-OSS тестировалась в трех режимах мышления: низком, среднем и высоком. Для оценки использовались пять режимов RAG и агентов, 16 моделей эмбеддингов и четыре набора данных:
- FinanceBench (финансовые рассуждения)
- HotpotQA (многошаговые вопросы)
- MultihopRAG (рассуждения с усилением поиска)
- PhantomWiki (синтетические пары вопрос-ответ)
Результаты оптимизации
При оптимизации для задержки и стоимости обнаружились неожиданные закономерности:
GPT-OSS 20b (низкий уровень мышления): быстрая, недорогая и стабильно точная конфигурация. Эта настройка неоднократно появлялась на границе Парето, что делает ее лучшим выбором по умолчанию для большинства ненаучных задач.
GPT-OSS 120b (средний уровень мышления): лучше всего подходит для задач, требующих глубоких рассуждений, таких как финансовые тесты. Используйте эту модель, когда точность решения сложных проблем важнее стоимости.
GPT-OSS 120b (высокий уровень мышления): дорогой и обычно ненужный. Оставьте его на крайний случай, когда другие модели не справляются. Для наших тестов он не добавил ценности.
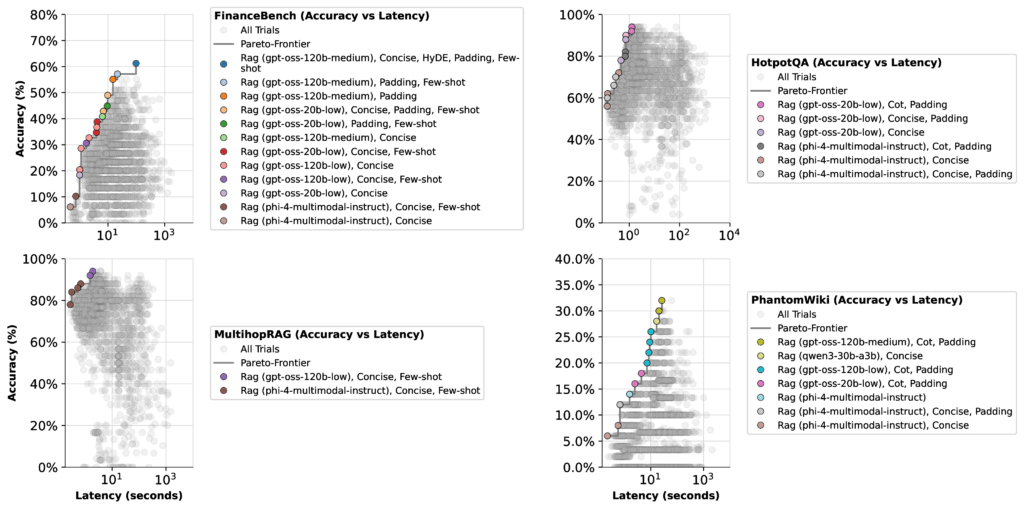
Рисунок 1: Оптимизация точности и задержки с помощью syftr
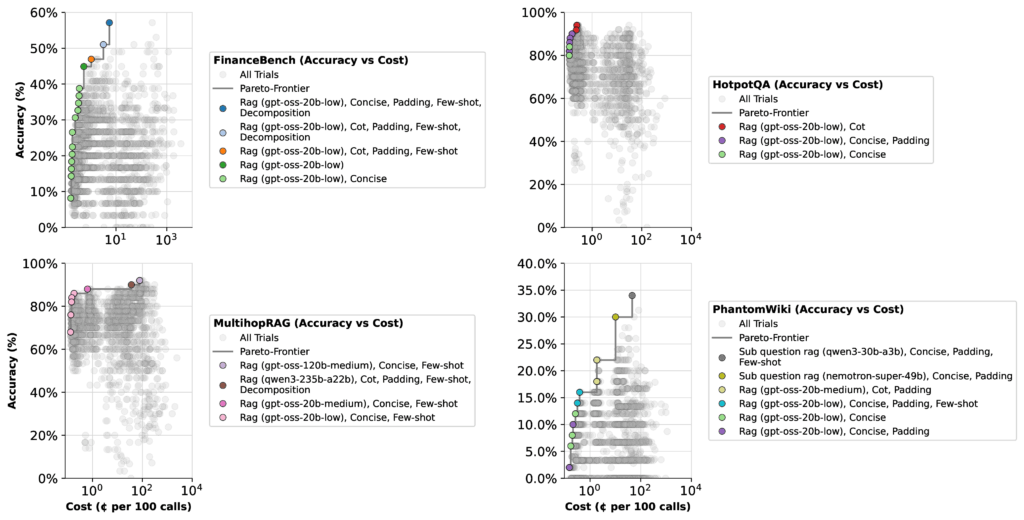
Рисунок 2: Оптимизация точности и стоимости с помощью syftr
Нюансы интерпретации результатов
Максимальный показатель точности языковой модели зависит не только от самой модели, но и от того, как оптимизатор взвешивает ее по сравнению с другими моделями в наборе. На примере FinanceBench:
При оптимизации для задержки все модели GPT-OSS (кроме высокого уровня мышления) показали схожие границы Парето. В этом случае у оптимизатора было мало причин концентрироваться на конфигурации 20b с низким уровнем мышления — ее максимальная точность составляла всего 51%.
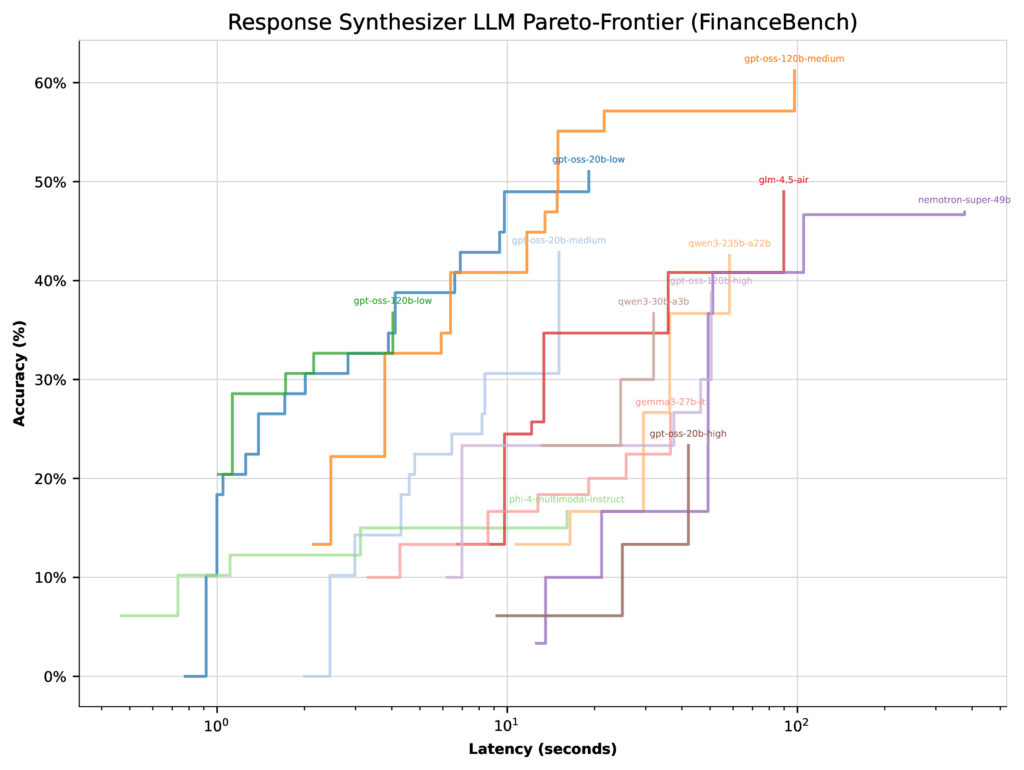
Рисунок 3: Границы Парето для каждой LLM при оптимизации задержки на FinanceBench
При оптимизации для стоимости картина резко меняется. Та же конфигурация 20b с низким уровнем мышления подскакивает до 57% точности, в то время как конфигурация 120b со средним уровнем мышления фактически падает на 22%. Почему? Потому что модель 20b намного дешевле, поэтому оптимизатор смещает больший вес в ее сторону.
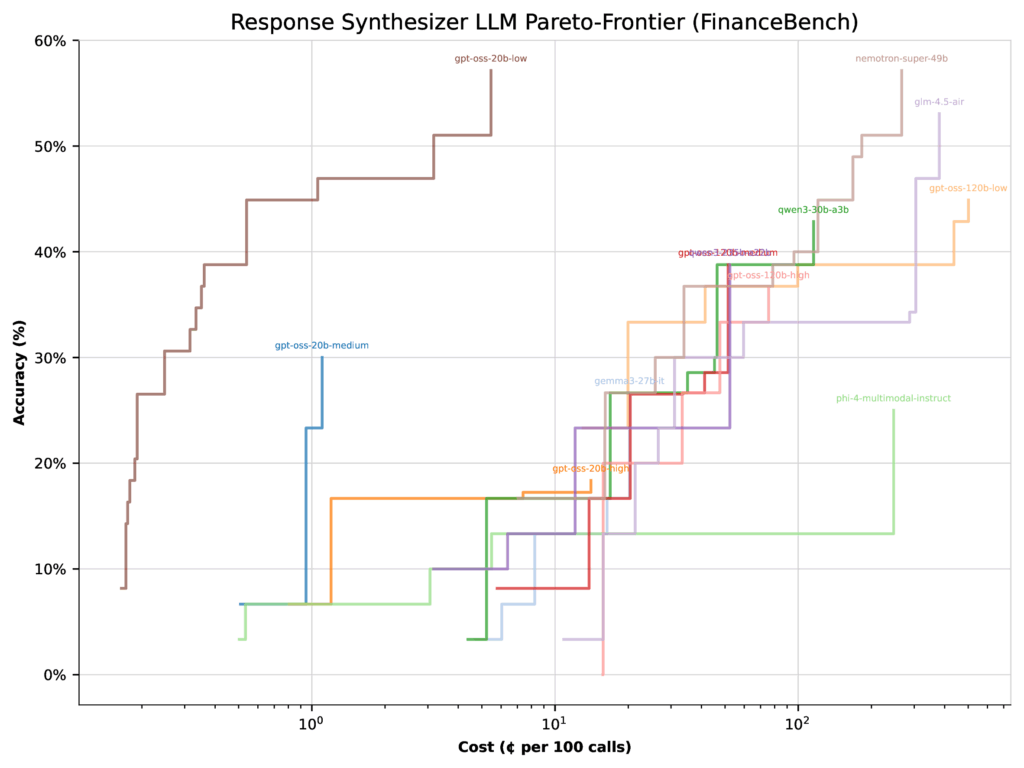
Рисунок 4: Границы Парето для каждой LLM при оптимизации стоимости на FinanceBench
Ирония ситуации в том, что индустрия годами верила в «чем больше — тем лучше», а теперь оказывается, что скромная 20-миллиардная модель с минимальным «мышлением» может обойти монстров на 120 миллиардов параметров. Это отличное напоминание, что настоящая оптимизация — это не про максимальную мощность, а про поиск идеального баланса между стоимостью, скоростью и качеством для конкретной задачи.
Практические выводы
Новые модели GPT-OSS показали сильные результаты в тестах — особенно 20b с низким уровнем мышления, которая часто опережала более дорогих конкурентов. Главный урок? Больше модели и больше усилий не всегда означают большую точность. Иногда платить больше — значит получать меньше.




