
Теперь на Hugging Face доступен RapidFire AI, который ускоряет тонкую настройку LLM в 20 раз
Hugging Face TRL теперь официально интегрируется с RapidFire AI, предоставляя разработчикам инструмент для ускорения экспериментов по тонкой настройке языковых моделей. Теперь пользователи могут сравнивать несколько конфигураций обучения одновременно даже на одном GPU, существенно сокращая время разработки.
Проблема традиционного подхода
При тонкой настройке языковых моделей команды разработчиков часто сталкиваются с ограничениями по времени и бюджету, что мешает сравнивать различные конфигурации обучения. Это приводит к субоптимальным результатам, поскольку оптимальные параметры остаются невыявленными.
RapidFire AI решает эту проблему, позволяя запускать несколько конфигураций TRL параллельно через новую адаптивную систему планирования на основе чанков данных. Внутренние тесты показывают увеличение пропускной способности экспериментов в 16-24 раза по сравнению с последовательным подходом.
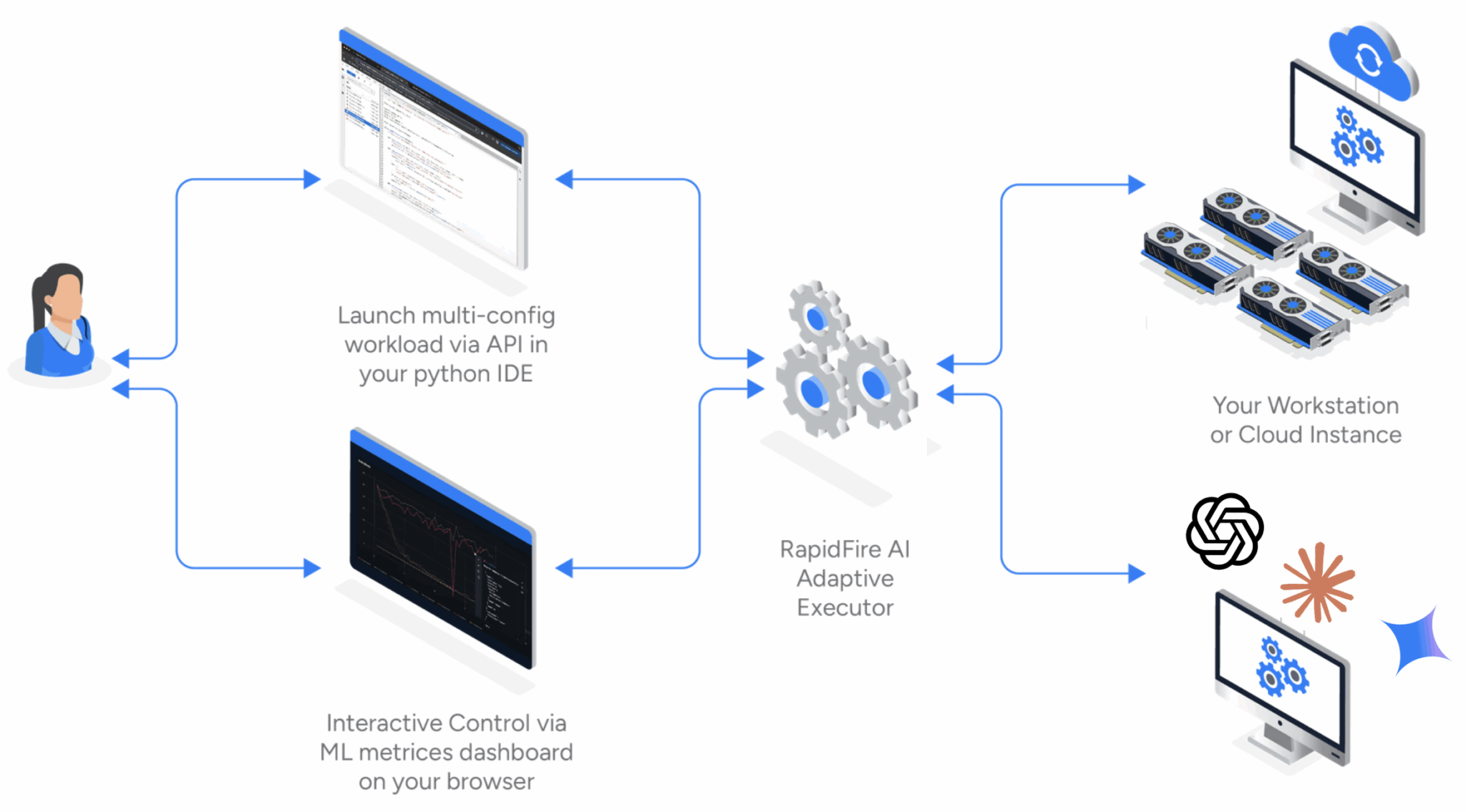
RapidFire AI устанавливает трехстороннюю связь между вашей IDE, панелью метрик и бэкендом выполнения на нескольких GPU
Ключевые возможности
- Drop-in обертки для TRL — RFSFTConfig, RFDPOConfig и RFGRPOConfig практически не требуют изменений кода, заменяя стандартные конфигурации TRL
- Адаптивное параллельное обучение — система разбивает датасет на чанки и циклически переключает конфигурации на границах чанков
- Интерактивное управление — возможность останавливать, возобновлять, удалять и клонировать запуски прямо из дашборда
- Оркестрация нескольких GPU — автоматическое распределение задач по доступным видеокартам через механизмы разделяемой памяти
- Дашборд на основе MLflow — мониторинг метрик, логов и управление экспериментами в реальном времени
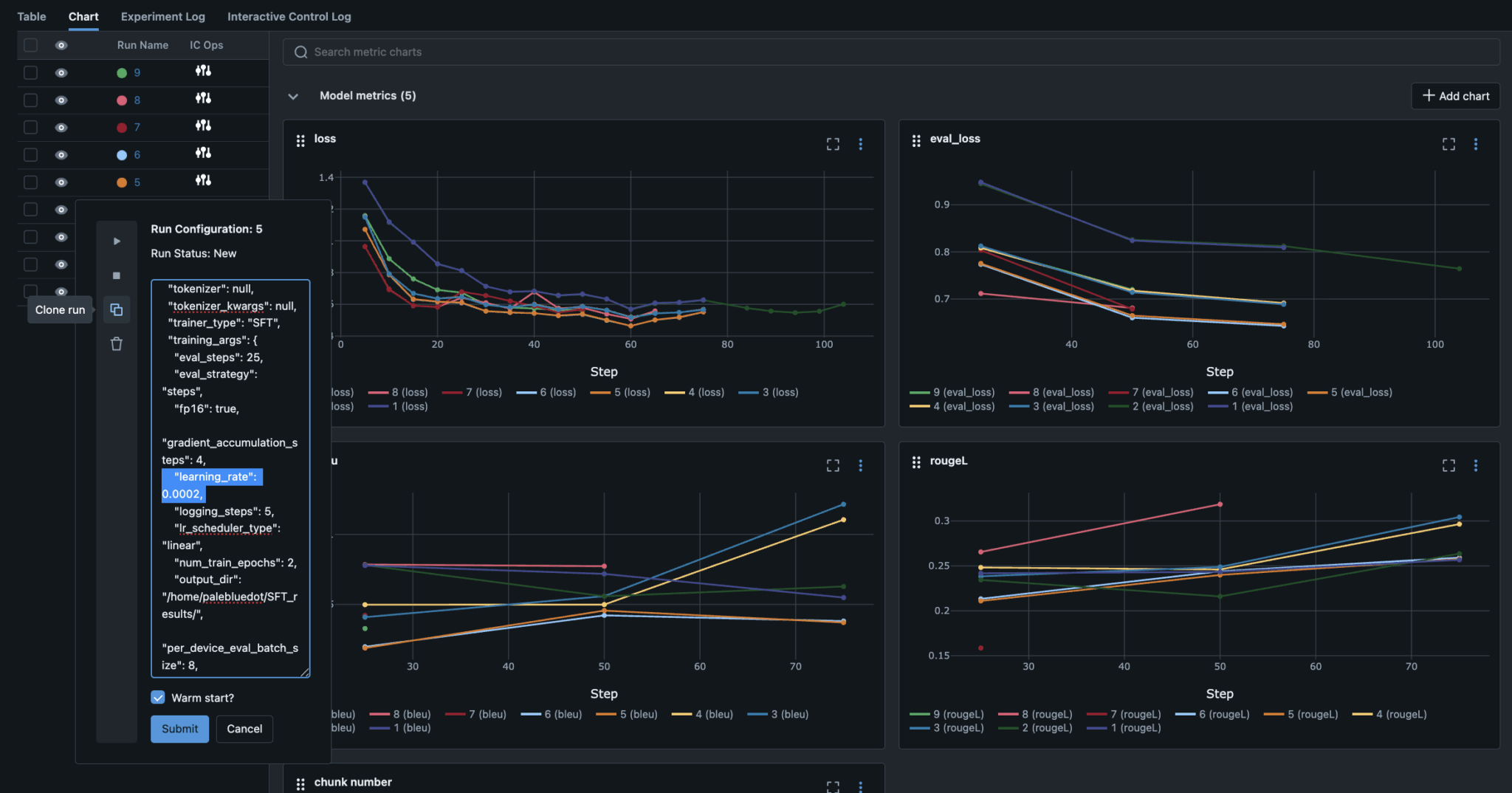
Клонирование перспективных конфигураций с модифицированными гиперпараметрами и возможностью теплого старта из весов родительского запуска
Техническая реализация
RapidFire AI случайным образом разбивает датасет на «чанки» и циклически переключает конфигурации языковых моделей между GPU на границах этих чанков. Это позволяет получить инкрементальные сигналы по оценочным метрикам для всех конфигураций значительно быстрее.
Автоматическое создание контрольных точек через эффективный механизм сохранения/загрузки моделей в разделяемой памяти обеспечивает плавное, стабильное и последовательное обучение.
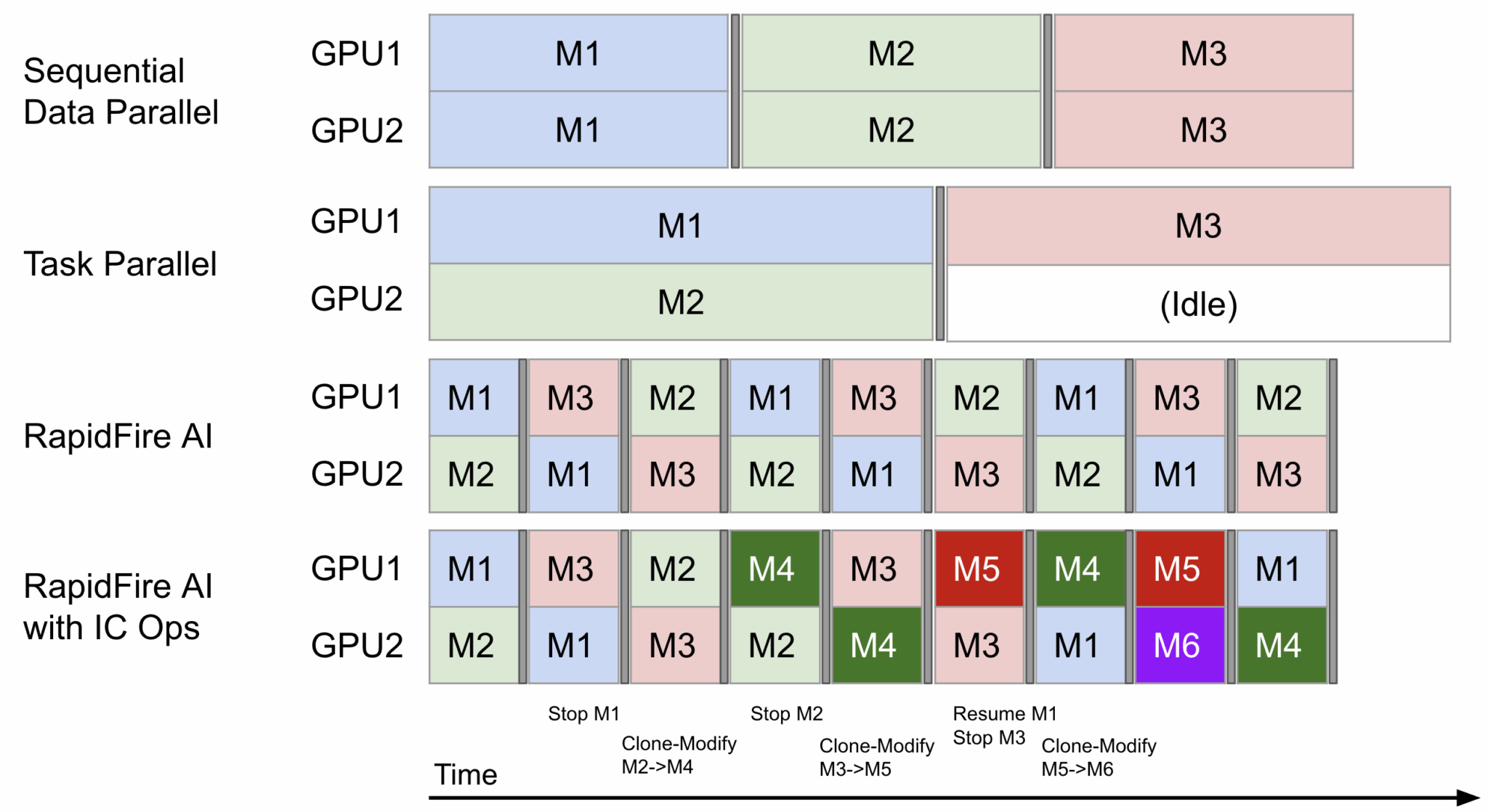
Сравнение последовательного, параллельного и RapidFire AI подходов: адаптивный планировщик максимизирует утилизацию GPU для нескольких конфигураций
Технология выглядит как долгожданное решение для практиков, уставших ждать неделями результаты экспериментов по тонкой настройке. Особенно впечатляет возможность перераспределять ресурсы на лету — это может кардинально изменить подход к ML-экспериментам, превратив их из статического процесса в динамический диалог с моделью. Хотя стоит посмотреть, как система поведет себя на действительно больших датасетах и сложных моделях.
Быстрый старт
Установка и запуск занимают менее минуты:
pip install rapidfireai # Аутентификация в Hugging Face huggingface-cli login --token YOUR_TOKEN # Обход текущей проблемы pip uninstall -y hf-xet # Инициализация и запуск RapidFire AI rapidfireai init rapidfireai start
Дашборд запускается по адресу http://localhost:3000, где можно мониторить и управлять всеми экспериментами.
Пример использования
Вот как выглядит обучение нескольких конфигураций одновременно даже на одном GPU:
from rapidfireai import Experiment
from rapidfireai.automl import List, RFGridSearch, RFModelConfig, RFLoraConfig, RFSFTConfig
from datasets import load_dataset
from transformers import AutoModelForCausalLM, AutoTokenizer
# Загрузка датасета и определение форматирования
dataset = load_dataset("bitext/Bitext-customer-support-llm-chatbot-training-dataset")
train_dataset = dataset["train"].select(range(128)).shuffle(seed=42)
def formatting_function(row):
return {
"prompt": [
{"role": "system", "content": "You are a helpful customer support assistant."},
{"role": "user", "content": row["instruction"]},
],
"completion": [{"role": "assistant", "content": row["response"]}]
}
dataset = dataset.map(formatting_function)
# Определение нескольких конфигураций для сравнения
config_set = List([
RFModelConfig(
model_name="TinyLlama/TinyLlama-1.1B-Chat-v1.0",
peft_config=RFLoraConfig(r=8, lora_alpha=16, target_modules=["q_proj", "v_proj"]),
training_args=RFSFTConfig(learning_rate=1e-3, max_steps=128, fp16=True),
),
RFModelConfig(
model_name="TinyLlama/TinyLlama-1.1B-Chat-v1.0",
peft_config=RFLoraConfig(r=32, lora_alpha=64, target_modules=["q_proj", "v_proj"]),
training_args=RFSFTConfig(learning_rate=1e-4, max_steps=128, fp16=True),
formatting_func=formatting_function,
)
])
# Запуск всех конфигураций параллельно с чанковым планированием
experiment = Experiment(experiment_name="sft-comparison")
config_group = RFGridSearch(configs=config_set, trainer_type="SFT")
def create_model(model_config):
model = AutoModelForCausalLM.from_pretrained(
model_config["model_name"],
device_map="auto", torch_dtype="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_config["model_name"])
return (model, tokenizer)
experiment.run_fit(config_group, create_model, train_dataset, num_chunks=4, seed=42)
experiment.end()
Производительность в реальных условиях
При запуске на машине с 2 GPU вместо последовательного обучения (Конфигурация 1 → ожидание → Конфигурация 2 → ожидание) обе конфигурации обучаются параллельно:
| Подход | Время до сравнительного решения | Утилизация GPU |
|---|---|---|
| Последовательный (традиционный) | ~15 минут | 60% утилизации |
| RapidFire AI (параллельный) | ~5 минут | 95%+ утилизации |
Это позволяет принять сравнительное решение в 3 раза быстрее на тех же ресурсах после обработки первого чанка данных вместо ожидания полного прохода по всему датасету для каждой конфигурации.
По материалам Hugging Face.



