Специализированные RL-агенты превосходят GPT-5 в корпоративных задачах
Как пишет Scale в своем блоге, корпорации сталкиваются с проблемой адаптации стандартных AI-моделей к своим уникальным рабочим процессам. Это требует создания специализированных агентов на основе обучения с подкреплением.
Проблема готовых решений
Общедоступные AI-модели демонстрируют впечатляющие общие возможности, но терпят неудачу там, где это критически важно — при выполнении специализированных задач, требующих работы с внутренними системами и проприетарными данными компаний.
Исследования Scale показывают, что обучение с подкреплением позволяет создавать агентов, которые значительно превосходят даже самые мощные модели вроде GPT-5:
- В страховом бенчмарке — 46,9% точности против 21,9% у лучшей готовой модели
- В юридическом бенчмарке — 83,6% точности против 79,6% с резким снижением галлюцинаций
Интересно наблюдать, как обучение с подкреплением из академической дисциплины превращается в практический инструмент для бизнеса. Результаты впечатляют, но главный вопрос — насколько масштабируема эта методология для средних компаний без ресурсов крупных корпораций.
Корпоративная data flywheel
В основе подхода лежит концепция data flywheel — цикла, где агенты взаимодействуют с корпоративными инструментами, получают обратную связь от сотрудников и генерируют данные для улучшения обучения.
Ключевые факторы успеха RL в корпоративной среде:
- Высококачественные данные, отражающие сложность реальных рабочих процессов
- Стабильная инфраструктура обучения
- Специфические критерии оценки и системы вознаграждений
- Сильная предварительная модель для эффективного обучения
Конкретные результаты
Text-to-SQL для страховой компании
Для глобальной страховой компании была реализована задача преобразования текста в SQL-запросы. Использовались исключительно self-hosted модели с открытым исходным кодом из-за требований безопасности данных.
Модели RL показали улучшение точности выполнения с 18,8% до 40,6% — более чем двукратный рост. Даже крупная модель Qwen3-Coder-480B-A35B достигла только 21,9% точности, что подчеркивает сложность задачи.
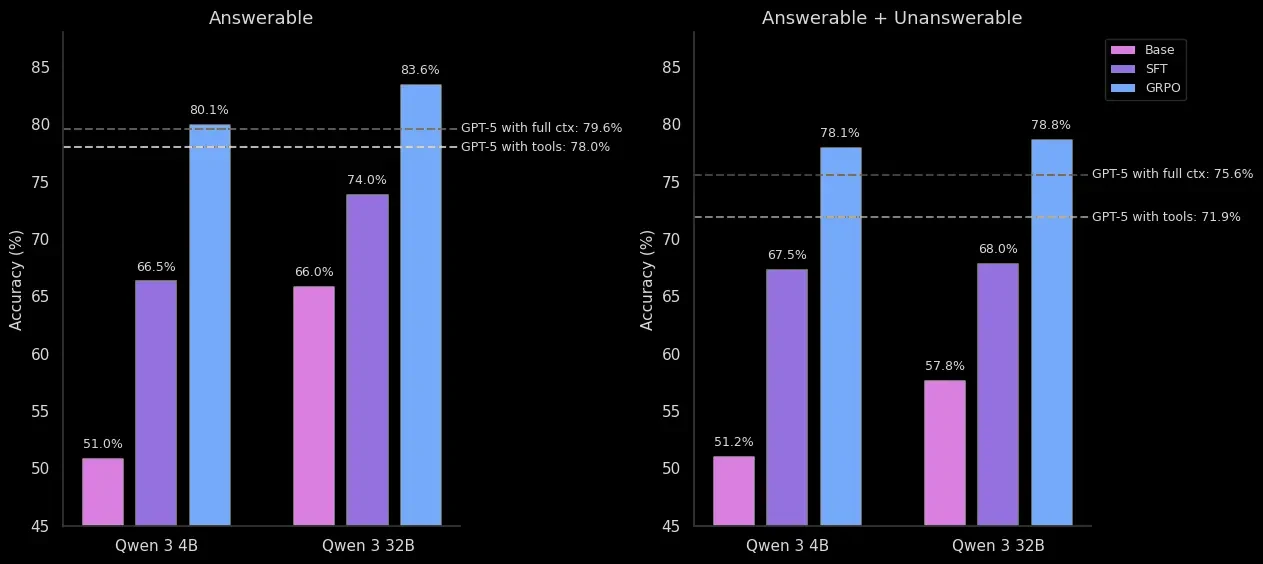
Юридическое извлечение и рассуждение
Для ведущей международной юридической фирмы разработана многошаговая задача поиска данных и юридических рассуждений. Модели имели доступ к трем инструментам поиска: выбор страниц, текстовый поиск и семантический поиск.
RL-обученные модели показали рост точности на 17-29% по сравнению с базовыми версиями, превосходя GPT-5 как в версии с инструментами, так и в версии с полным контекстом.
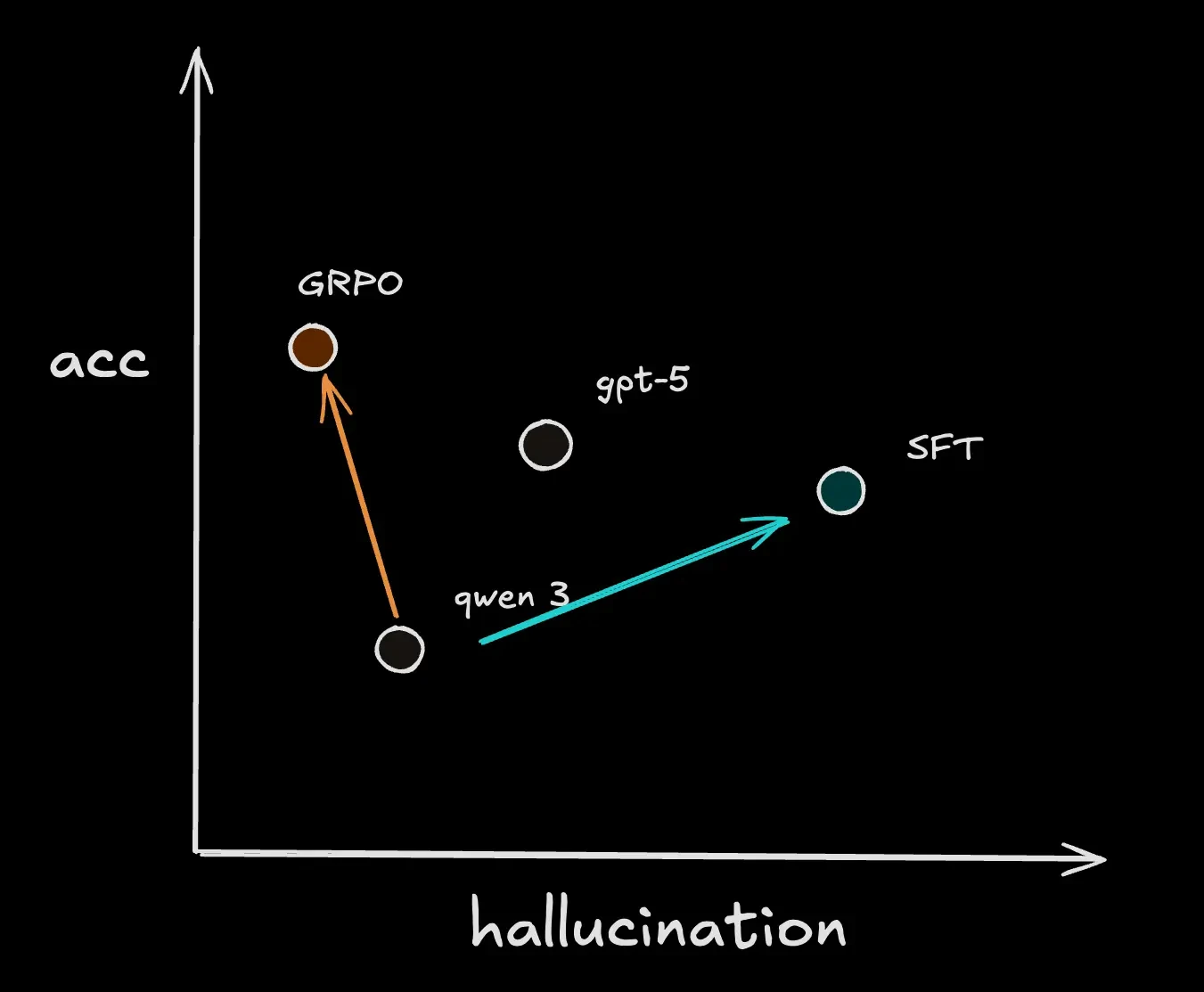
Практические импликации
Методология демонстрирует, что специализированные агенты могут достигать уровня точности, недоступного даже самым передовым универсальным моделям. Это особенно важно для отраслей с жесткими требованиями к точности и конфиденциальности данных.
Текущие исследования расширяются в сторону многошаговых сред с инструментами, где выполнение SQL становится интерактивным процессом, позволяя агентам итеративно отлаживать и проверять запросы.
Забавно, что пока все говорят о размере моделей, реальный прорыв происходит в области специализации. Похоже, будущее корпоративного AI не за гигантскими универсальными моделями, а за армией узкоспециализированных агентов, каждый из которых отлично справляется со своей задачей.