
Исследование выявило, что языковые модели при усложнении задач упрощают мышление
Крупномасштабное исследование более 170 000 трасс рассуждений открытых моделей показало, что языковые модели ИИ при усложнении задач переходят на простые, шаблонные стратегии мышления. Новая система категоризации когнитивных процессов позволяет точно определить, каких способностей не хватает моделям и когда дополнительные подсказки в промптах действительно помогают.
Согласно исследованию «Cognitive Foundations for Reasoning and Their Manifestation in LLMs», современные тесты для языковых моделей не измеряют их реальные способности к рассуждению. Авторы отмечают, что существующие подходы фокусируются в основном на правильности конечного ответа, тогда как остается неизвестным, действительно ли модель рассуждает или просто повторяет знакомые паттерны.
Когнитивные строительные блоки мышления моделей
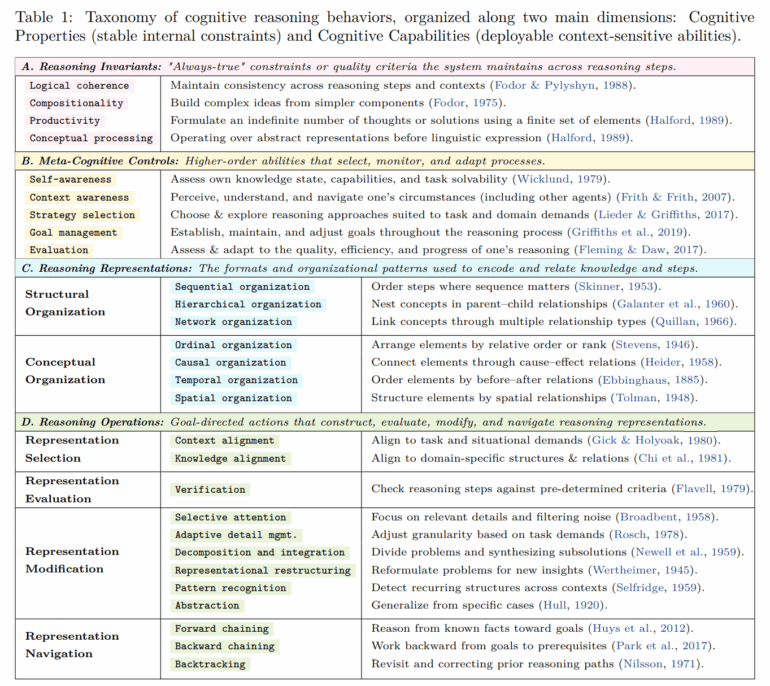
Для сравнения трасс рассуждений исследователи определили 28 повторяющихся компонентов мышления. К ним относятся:
- Базовые правила, такие как соблюдение последовательности и комбинирование простых концепций в более сложные
- Поведения самоуправления, включая постановку целей, осознание неопределенности и проверку прогресса
- Различные способы организации информации — в виде списка, дерева, причинно-следственной цепи или пространственного образа
- Типичные ходы рассуждений: декомпозиция проблем, проверка промежуточных шагов, откат ошибочного подхода или обобщение примеров
Используя эту систему, команда аннотировала каждый фрагмент трассы рассуждений, где появлялся один из этих компонентов.
Автопилот мышления при сложных задачах
Результаты демонстрируют четкую закономерность. На хорошо структурированных задачах, таких как классические математические проблемы, модели используют относительно разнообразный набор компонентов мышления. Но по мере увеличения неопределенности задач — например, в открытых кейс-анализах или моральных дилеммах — модели сужают свое поведение. Линейная пошаговая обработка выходит на первый план вместе с простыми проверками правдоподобия и прямым рассуждением от данных фактов.
Статистический анализ показывает, что успешные решения сложных задач коррелируют с противоположным поведением: большим структурным разнообразием, иерархической организацией, построением причинно-следственных сетей, рассуждением от цели к условиям и целенаправленным переосмыслением. Эти паттерны гораздо чаще встречаются в человеческих трассах. Люди описывают свой подход, оценивают промежуточные результаты и гибко переключаются между стратегиями и представлениями.
Документированные в исследовании примеры делают этот контраст осязаемым. В логической задаче с шахматной доской человек решает ее коротким аргументом на основе абстракции цветового расположения. Трасса DeepSeek-R1 для той же задачи занимает более 7000 токенов, перечисляя координаты по одной, перескакивая между гипотезами и многократно пытаясь проверить их, прежде чем в конечном итоге прийти к абстракции.
Ирония в том, что мы создаем системы, способные генерировать тысячи токенов рассуждений, но неспособные к простейшим метакогнитивным актам — заметить собственную неопределенность или сменить стратегию. Это напоминает студента, который усердно переписывает учебник, но не понимает его содержания. Пока модели не научатся рефлексировать о собственном мышлении, их рассуждения останутся лишь сложной симуляцией.
Направленные рассуждения работают только для сильных моделей
Команда также проверила, можно ли превратить наиболее успешные паттерны рассуждений в практические промпты. Из общих структур успеха они вывели инструкции, предписывающие процесс мышления — например, сначала выбрать релевантную информацию, затем построить структуру и только после этого делать выводы.
Модели типа Qwen3-14B, Qwen3-32B, R1-Distill-Qwen-14B/32B, R1-Distill-Llama-70B и Qwen3-8B показали явный рост точности, в некоторых случаях более 20 процентов относительного улучшения. В задачах дилемм и кейс-анализа точность увеличивалась до 60 процентов в отдельных сценариях. Сложные, плохо структурированные категории типа Dilemma, Diagnosis-Solution и Case Analysis получали наибольшую выгоду.
Для меньших или слабых моделей эффект иногда оказывался обратным. Hermes-3-Llama-3-8B и DeepScaleR-1.5B демонстрировали двузначное относительное падение в среднем и теряли до 70 процентов точности на некоторых хорошо структурированных задачах. R1-Distill-Qwen-7B и OpenThinker-32B реагировали непоследовательно, с улучшениями в одних категориях и ухудшениями в других.

Авторы приходят к выводу о существовании порога способностей: только модели с достаточно сильными навыками рассуждения и следования инструкциям могут эффективно использовать детальное когнитивное структурирование. Результаты также предполагают, что дополнительные структурные подсказки менее полезны на хорошо структурированных проблемах и могут конфликтовать с выученными эвристиками. Остается неясным, раскрывает ли такое руководство латентные способности или в основном оптимизирует извлечение обученных паттернов.
Ограничения исследовательского сообщества
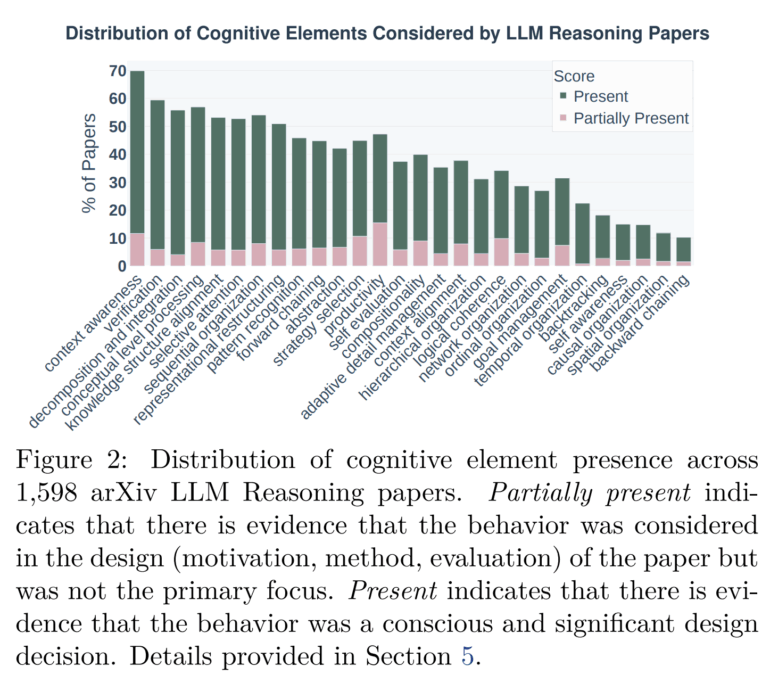
Мета-анализ 1598 статей с arXiv показывает, что исследования рассуждений LLM в значительной степени концентрировались на легко измеримых поведениях, таких как пошаговые объяснения и декомпозиция проблем. Метакогниция и пространственная или временная организация редко получают внимание — хотя эмпирический анализ трасс рассуждений предполагает, что они критически важны для сложных, плохо структурированных задач.
В целом исследователи утверждают, что область по-прежнему опирается на узкую, линейную декомпозиционную систему, упускающую множество значительных когнитивных феноменов.
По материалам The Decoder.





