
Google объединила Gemini CLI и GKE для оптимизации LLM-развертывания
Google представила интеграцию Gemini CLI с Kubernetes Engine, которая позволяет автоматизировать развертывание языковых моделей и оптимизировать затраты на инфраструктуру. Решение призвано заменить месяцы ручной настройки готовыми манифестами и рекомендациями на основе данных.
Автоматизация выбора и развертывания моделей
Новый инструмент Gemini CLI в сочетании с расширением gke-mcp позволяет разработчикам использовать естественный язык для управления LLM-рабочими нагрузками. Система поддерживает Model Context Protocol (MCP), что обеспечивает интеллектуальные рекомендации по выбору оборудования и конфигурации.
Установка выполняется простыми командами:
brew install gemini-cli gemini extensions install https://github.com/GoogleCloudPlatform/gke-mcp.git
После установки разработчики могут задавать вопросы на естественном языке:
- Какие 3 самые дешевые модели доступны в GKE Inference Quickstart?
- Как производительность этой модели отличается при работе на разных ускорителях?
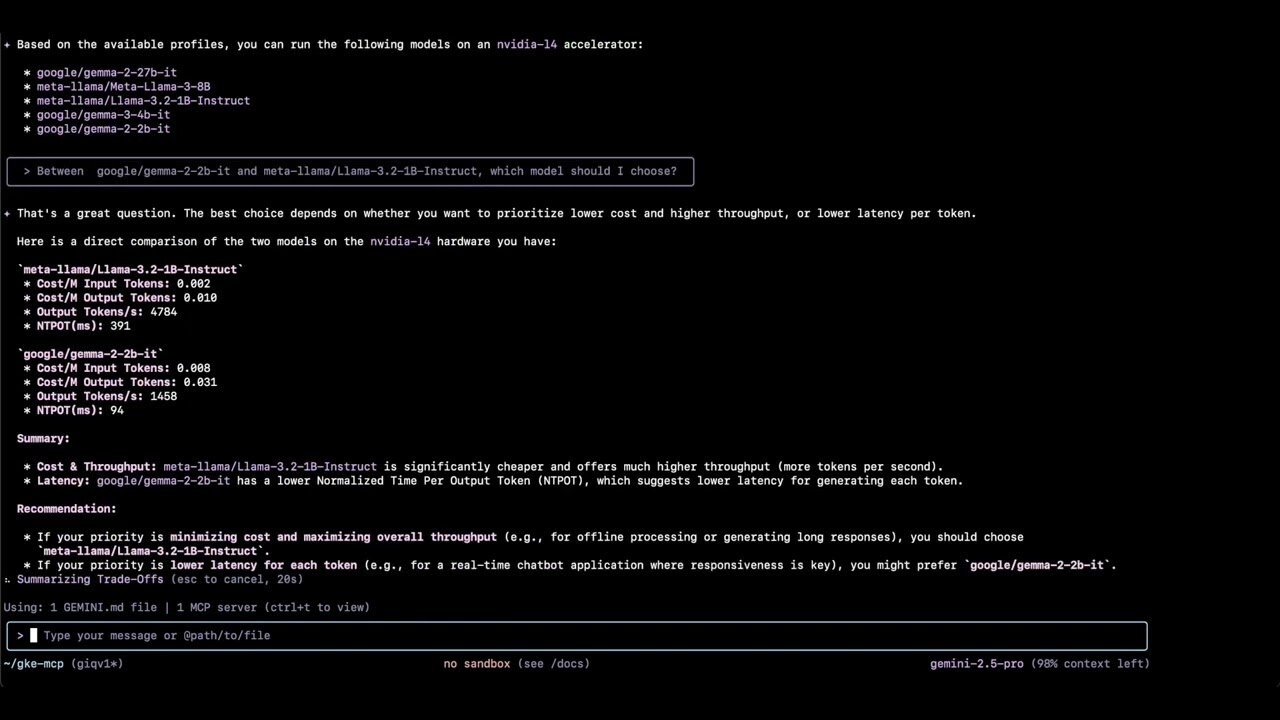
- Как выбрать между двумя моделями?
- Сгенерируйте манифест для этой модели на этом ускорителе
Оптимизация затрат при сохранении производительности
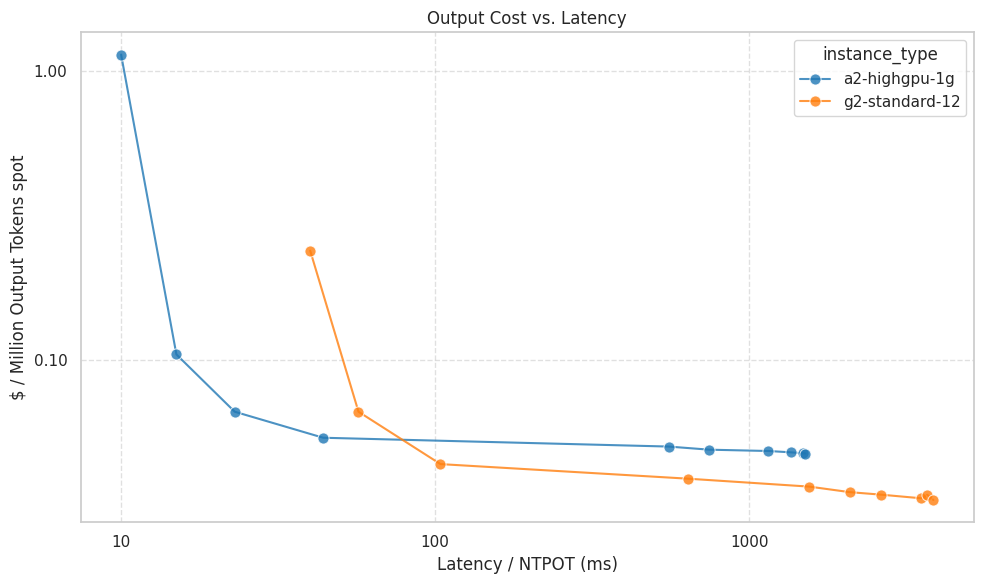
Выбор правильного оборудования для инференса требует балансировки между производительностью и стоимостью. Inference Quickstart предоставляет данные о производительности и затратах для различных конфигураций ускорителей, основанные на бенчмарках Google.
Как показывает практика, достижение минимальной задержки для моделей вроде Gemma 3 4b на vLLM значительно увеличивает стоимость. Это происходит из-за необходимости жертвовать эффективностью батчинга запросов ради низкой латентности.
Интересно, что Google решила автоматизировать именно ту часть ML-операций, которая традиционно была самой болезненной для команд — выбор оптимальной конфигурации инфраструктуры. Вместо бесконечных экспериментов с разными GPU и настройками теперь можно получить рекомендации на основе реальных данных. Правда, возникает вопрос: насколько эти рекомендации будут объективны, учитывая что Google продвигает собственные TPU и облачные сервисы.
Расчет стоимости на основе токенов
При самостоятельном хостинге моделей на GKE оплата взимается за время использования ускорителей, а не за отдельные токены. Inference Quickstart использует следующую формулу для расчета стоимости токенов:
$/output token = Accelerator $/s / (1/4 input tokens/s + output tokens/s) где $/input token = ($/output token) / 4
Эта формула предполагает, что стоимость выходного токена в четыре раза превышает стоимость входного. Такой подход основан на том, что фаза предварительной обработки (префилл) является высокопараллельной операцией, тогда как генерация выходных токенов — последовательный процесс.
Ключевым преимуществом является возможность настройки соотношения стоимости токенов в зависимости от характеристик конкретной рабочей нагрузки.
По материалам Google Cloud Blog.



