Together AI установила рекорд скорости для открытых языковых моделей
Платформа Together AI объявила о достижении беспрецедентной производительности в серверных вычислениях для крупнейших открытых языковых моделей, включая GPT-OSS, Qwen, Kimi и DeepSeek. Согласно данным независимых бенчмарков Artificial Analysis, компания демонстрирует до двукратного превосходства в скорости генерации текста по сравнению с конкурентами.
Результаты производительности
Тестирование показало впечатляющие результаты для ключевых моделей:

GPT-OSS-20B: почти в 2 раза быстрее ближайшего конкурента
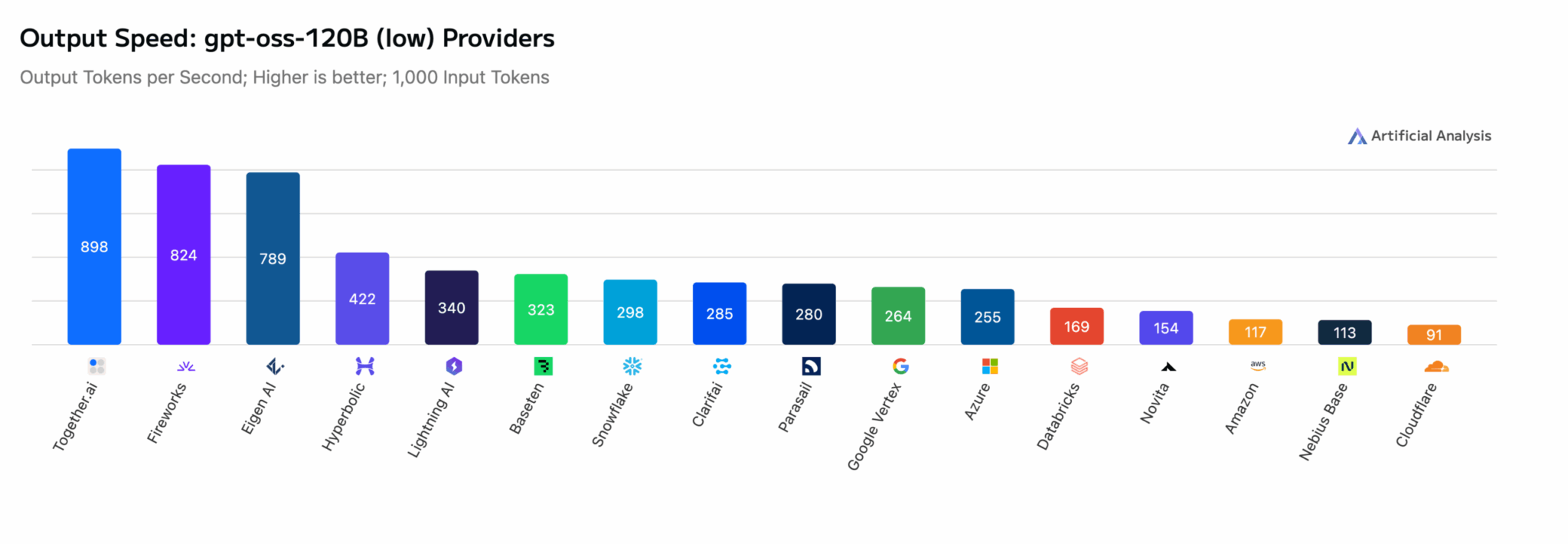
GPT-OSS-120B: на 10% быстрее следующего провайдера
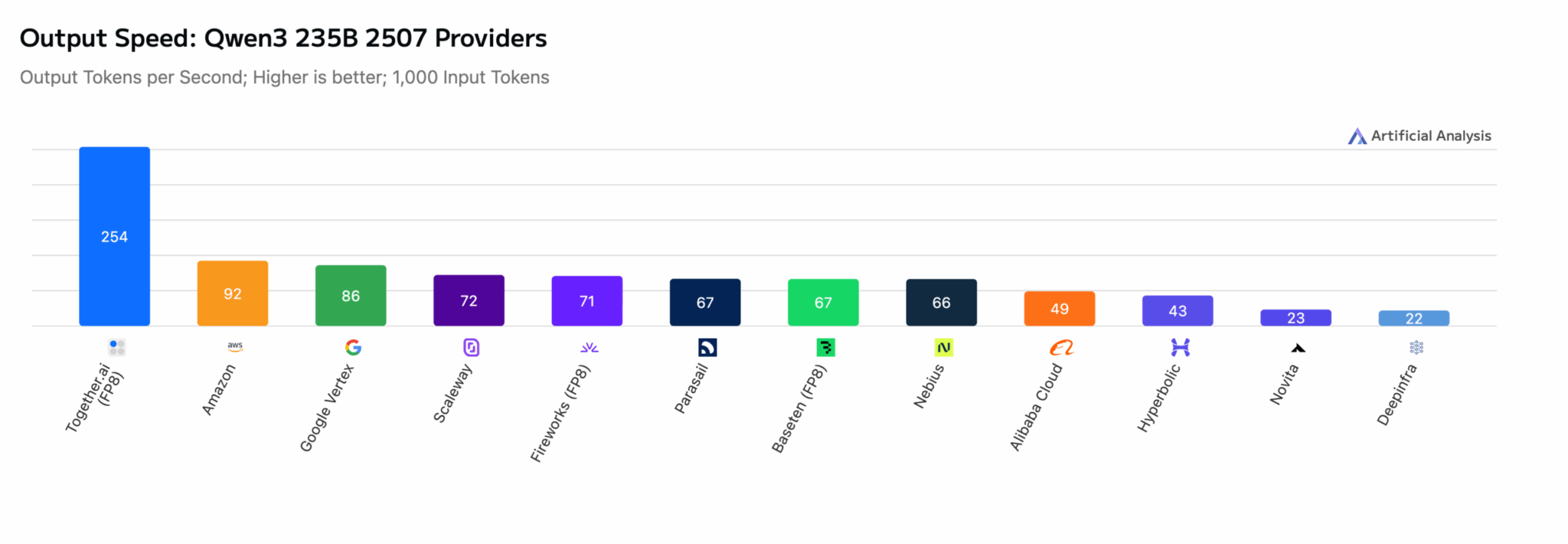
Qwen3-235B-2507: более чем в 2,75 раза быстрее ближайшего конкурента
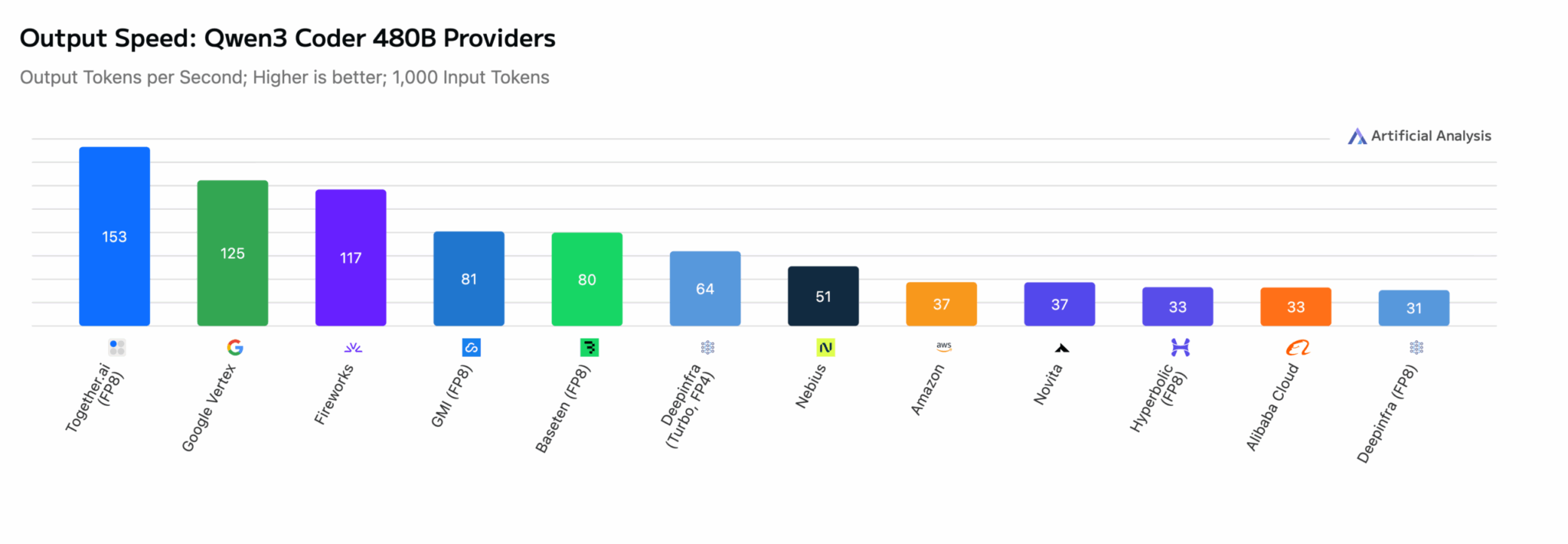
Qwen3-Coder-480B: на 22% быстрее следующего провайдера
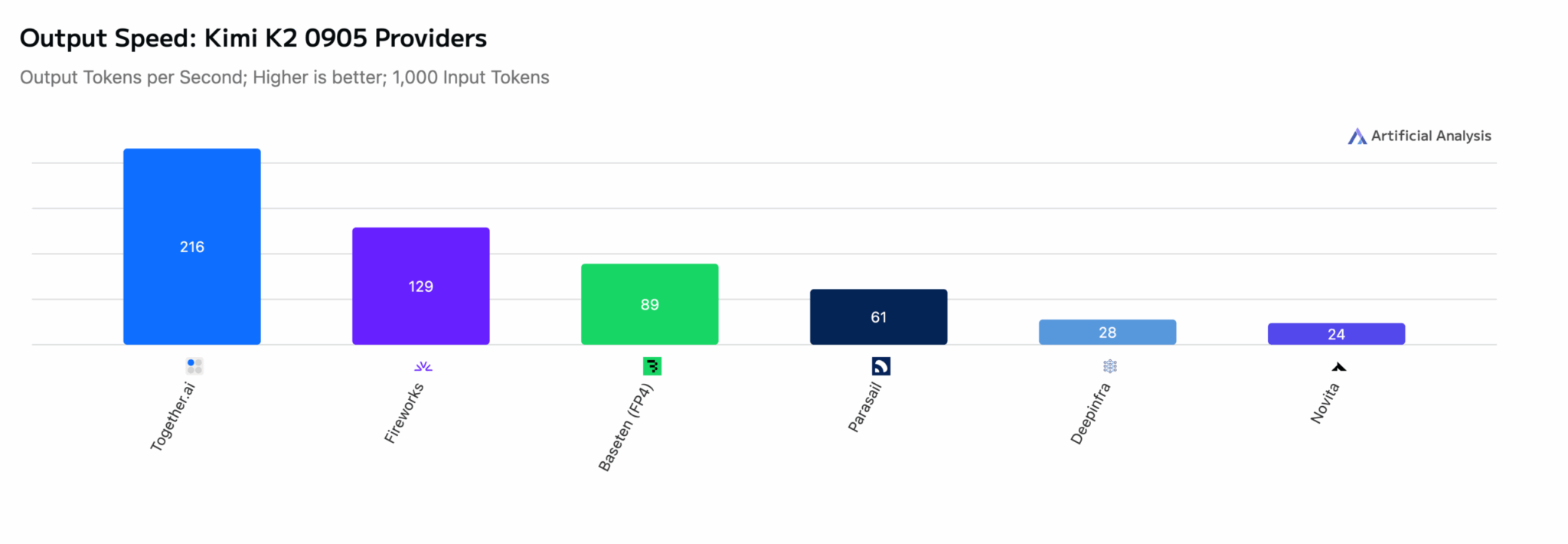
Kimi-K2-0905: на 65% быстрее ближайшего конкурента
DeepSeek-V3.1: на 10% быстрее следующего провайдера
DeepSeek-R1-0528: на 13% быстрее ближайшего конкурента
Технические инновации
Достигнутая производительность стала результатом комплексной оптимизации всей технологической цепочки:
Современное GPU-оборудование с оптимизацией движка
Компания полностью переработала инфраструктуру вычислений под архитектуру NVIDIA Blackwell, включая систему GB200 NVL72. Оптимизация затронула не отдельные компоненты, а всю систему целиком — вычислительные ядра, организацию памяти, графы выполнения и планирование задач.
Together Kernels
Разработано новое поколение высокопроизводительных GPU-ядер, включая оптимизированные FlashAttention-4 ядра и объединенные ядра для MoE-архитектур, которые сочетают маршрутизацию и экспертные FFN-сети.
Turbo оптимизация
- Квантование: переход к низкоразрядным форматам FP8 и FP4 с сохранением качества модели
- Алгоритм Speculator: производственная реализация спекулятивного декодирования с адаптивными стратегиями принятия решений
- Масштабируемое обучение: конвейер обучения драфт-моделей для целевых моделей объемом до 1T+ параметров
Интересно наблюдать, как гонка за производительностью выходит на новый уровень. Двукратное ускорение — это уже не просто маркетинговая фишка, а реальное конкурентное преимущество для бизнеса. Особенно впечатляет работа с квантованием — переход к FP4 без потери качества выглядит как серьезный прорыв. Впрочем, остается вопрос, насколько эта скорость сохранится при массовом использовании и не станет ли узким местом что-то другое, например, пропускная способность сети.
Перспективы развития
Компания продолжает работу над дальнейшим улучшением производительности:
- Еще более быстрая генерация для специализированных доменов
- Новые стратегии генерации за пределами спекулятивного декодирования
- Расширенная поддержка гибридного квантования
По материалам Together AI.