
Новая архитектура памяти для ИИ-агентов GAM превосходит RAG в тестах
Исследовательская группа из Китая и Гонконга разработала революционную архитектуру памяти для ИИ-агентов, предназначенную для минимизации потери информации во время длительных взаимодействий, сообщает The Decoder.
Память остается одним из самых слабых мест современных ИИ-агентов. Когда разговоры или задачи затягиваются, модели сталкиваются с ограничениями контекстного окна или теряют детали — феномен, известный как «гниение контекста».
В новой научной работе исследователи представили «Общую Агентскую Память» (General Agentic Memory, GAM) как решение этой проблемы. Система сочетает сжатие данных с механизмом глубокого исследования, применяя принцип «компиляции по требованию» к памяти ИИ — процесс оптимизации кода непосредственно в момент выполнения.
В то время как предыдущие подходы полагались на статические сводки, созданные заранее, исследователи утверждают, что это неизбежно приводит к потере информации. Детали, которые кажутся неважными при сохранении, могут оказаться критическими позже, но к тому моменту они уже будут сжаты и утеряны.
Двухкомпонентная архитектура
GAM использует двойную архитектуру, состоящую из двух специализированных компонентов: «Запоминателя» (Memorizer) и «Исследователя» (Researcher). Запоминатель работает в фоновом режиме во время взаимодействий. Пока он создает простые сводки, он также архивирует полную историю разговора в базе данных под названием «хранилище страниц». Он сегментирует разговор на страницы и помечает их контекстом для облегчения поиска.
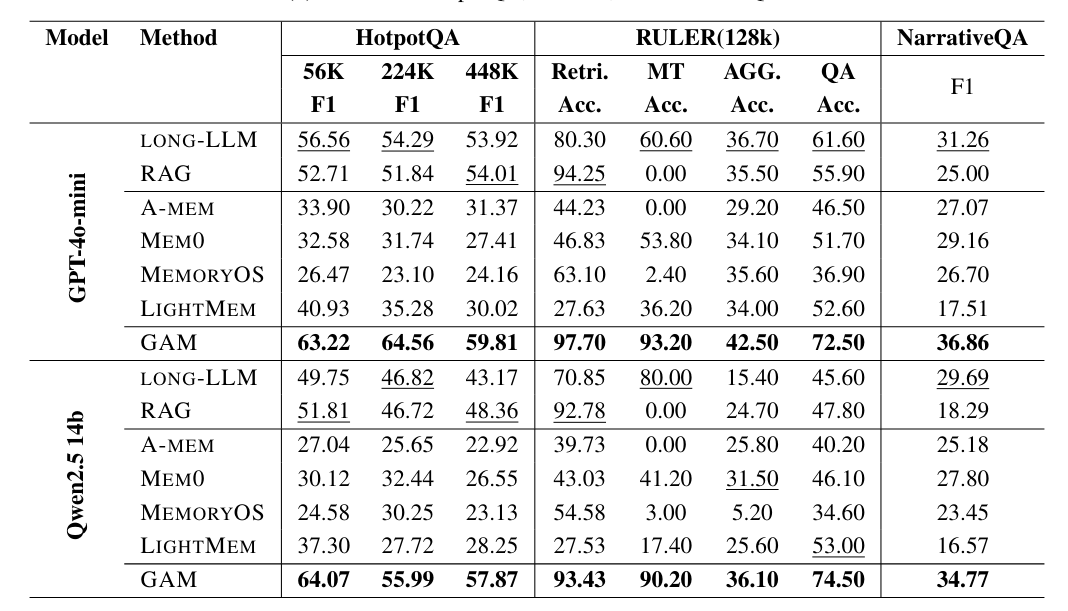
Исследователь активируется только тогда, когда агент получает конкретный запрос. Вместо простого поиска в памяти он проводит «глубокое исследование» — анализируя запрос, планируя стратегию поиска и используя инструменты для просмотра хранилища страниц. Он использует три метода: векторный поиск для тематических сходств, поиск BM25 для точных ключевых слов или прямой доступ через идентификаторы страниц. Процесс итеративный. Агент проверяет результаты поиска и размышляет, достаточно ли информации. При необходимости он запускает новые запросы перед генерацией ответа.
Превосходство над RAG и моделями с длинным контекстом
Команда протестировала GAM против традиционных методов, таких как Retrieval-Augmented Generation (RAG), и моделей с массивными контекстными окнами, таких как GPT-4o-mini и Qwen2.5-14B.
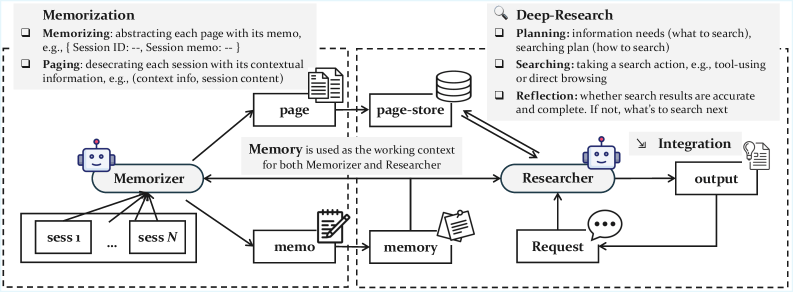
Согласно научной работе, GAM превзошла конкурентов во всех тестах. Наибольший разрыв наблюдался в задачах, требующих связывания информации за длительные периоды. В тесте RULER, который отслеживает переменные на протяжении многих шагов, GAM достигла точности свыше 90 процентов, в то время как традиционные подходы RAG и другие системы хранения в основном провалились.
Исследователи считают, что GAM успешна, потому что ее итеративный поиск находит скрытые детали, которые упускают сжатые сводки. Система также хорошо масштабируется с вычислительной мощностью: предоставление Исследователю большего количества шагов и времени на размышление дополнительно улучшает качество ответов.
Код и данные проекта доступны на GitHub.
Архитектура GAM — это именно тот тип инноваций, который нужен ИИ-агентам для перехода от демонстрационных прототипов к реальным рабочим инструментам. Идея «компиляции по требованию» для памяти гениальна — она решает фундаментальную проблему компромисса между объемом и точностью. Но главный вопрос в том, как эта система будет работать в реальных условиях с ограниченными вычислительными ресурсами и требованиями к скорости отклика.
Новые подходы к управлению контекстом
Другие лаборатории также решают проблему памяти. Anthropic недавно сместила фокус на «инженерию контекста», активно курируя все состояние контекста через компактные сводки или структурированные заметки, а не просто оптимизируя промпты.
Аналогично, Deepseek представила новую OCR-систему, которая обрабатывает текстовые документы как сильно сжатые изображения. Этот подход значительно экономит вычисления и токены, потенциально служа эффективным долгосрочным хранилищем для чат-ботов, сохраняя старые сегменты разговора в виде файлов изображений.
Тем временем исследователи в Шанхае предложили «Семантическую Операционную Систему», предназначенную для работы в качестве пожизненной памяти для ИИ. Эта система будет управлять контекстом как человеческий мозг, выборочно адаптируя и забывая знания, чтобы превращать временную информацию в постоянные структурированные воспоминания.


