
Бенчмарк ARC-AGI — больше не препятствие для ИИ-моделей
По сообщению The Decoder, некогда считавшийся непреодолимым барьером для ИИ бенчмарк ARC-AGI стал очередной жертвой безжалостной оптимизации машинного обучения. То, что создавалось как тест на подлинный интеллект, превратилось в очередную задачу для специализированных алгоритмов.
От абстрактного мышления к оптимизационной задаче
Когда исследователь ИИ Франсуа Шолле представил ARC (Abstraction and Reasoning Corpus) в 2019 году, он позиционировал его как антидот к парадигме глубокого обучения. Целью было измерение «эффективности приобретения навыков» — того, насколько хорошо система обучается новым задачам, а не того, какой объем данных она может запомнить.
Исследователи годами бились над этими цветными головоломками. Пока языковые модели крушили другие бенчмарки, показатели успеха в ARC оставались низкими. Для одних он стал «Полярной звездой» исследований ИИ, для других — демонстрацией ограничений масштабирования больших моделей.
Эта динамика изменилась с появлением специализированных моделей рассуждений и таких методов, как Test-Time Training (TTT). Переломный момент наступил в декабре 2024 года, когда модель OpenAI o3-preview внезапно показала результат свыше 75% на ARC-AGI-1. То, что начиналось как тест на человекообразную абстракцию, быстро становится целью оптимизации для алгоритмов обучения с подкреплением и поиска.
Прорыв Poetiq: специализация против обобщения
Новые результаты от компании Poetiq свидетельствуют, что оригинальный бенчмарк ARC-AGI-1 фактически решен. В своем объявлении компания утверждает, что ее системы, построенные на моделях OpenAI и Google, достигли максимальной производительности на первом наборе данных. Что еще важнее — система якобы превзошла человеческий средний показатель в 60% на значительно более сложном наборе данных ARC-AGI-2.
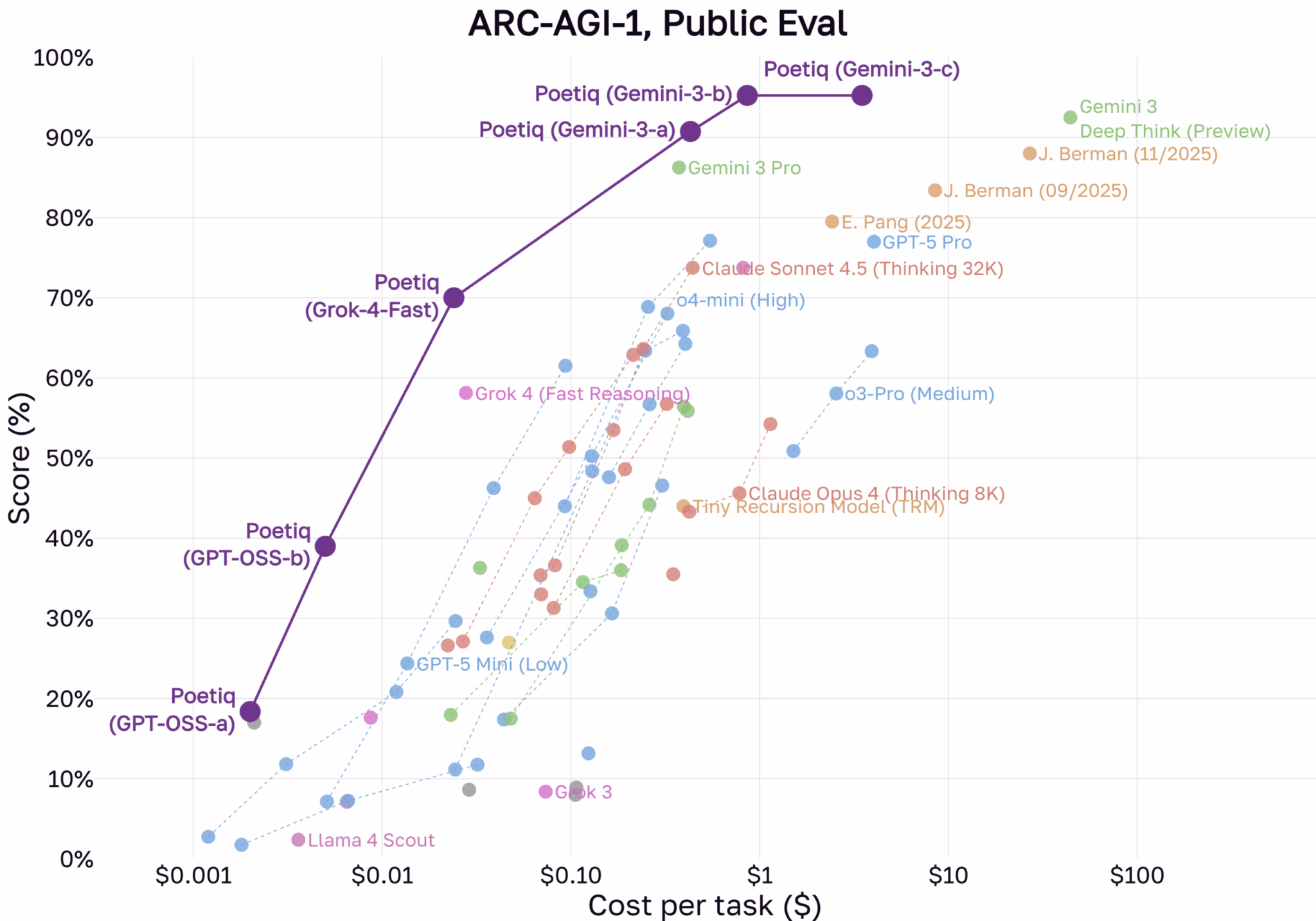
Подход Poetiq объединяет продвинутые языковые модели, включая Gemini 3 и GPT-5.1, с моделями с открытым исходным кодом, интегрированными в пользовательскую архитектуру. Согласно Poetiq, система работает в итеративном цикле: генерирует предлагаемые решения, оценивает обратную связь и уточняет ответы через самопроверку перед финализацией результата.
Ирония ситуации в том, что тест, созданный для проверки подлинного интеллекта, пал под натиском узкоспециализированных методов оптимизации. Это классическая история индустрии: сначала создаем сложный бенчмарк, затем превращаем его в очередную цель для гипероптимизации. Настоящее обобщение по-прежнему остается недоступным — мы просто научились лучше играть в конкретные игры.
Проблема контаминации данных
Эти высокие результаты в настоящее время применимы только к «публичным» наборам данных, а не к «полуприватным» наборам, хранящимся у администраторов ARC. В собственном анализе Poetiq отмечает, что многие базовые LLM показывают значительно худшие результаты при переходе от публичных наборов оценки к полуприватным.
Вероятный виновник — «контаминация данных»: публичные бенчмарки часто попадают в тренировочные данные для больших моделей. Истинное обобщение доказывается только на задачах, которые модель определенно никогда не видела. Poetiq ожидает, что ее собственные системы покажут аналогичное падение производительности на ARC-AGI-1 по этой причине.
Однако более новый ARC-AGI-2 может быть более устойчив к этому эффекту. Poetiq описывает наборы как «более точно откалиброванные» и утверждает, что ее система никогда не обучалась на задачах ARC-AGI-2, хотя базовые модели, которые она использует, возможно, обучались.
Сдвиг парадигмы: адаптация во время тестирования
Шолле внимательно наблюдал за этой эволюцией. Он рассматривает недавние успехи как свидетельство фундаментального стратегического сдвига в разработке ИИ.
Описывая результаты моделей рассуждений, таких как o3, как «неожиданный и важный скачок в возможностях ИИ», Шолле утверждает, что старая стратегия масштабирования интеллекта через более крупные модели и больше данных наталкивается на стену с задачами вроде ARC. Вместо этого область вступила в эру адаптации во время тестирования.
Модели больше не являются статичными респондентами. Они адаптируются во время выполнения, используя методы, аналогичные синтезу программ и цепочечным рассуждениям, чтобы перенастраиваться под конкретные проблемы. Для Шолле это подтверждает его теорию о том, что интеллект — это процесс адаптации, а не статичное хранилище знаний.
Он утверждает, что решение ARC является необходимым шагом к ОИИ, но не самим ОИИ. Текущие модели все еще терпят неудачу в базовых задачах и не имеют глубокого понимания мира. Целью бенчмарка было подтолкнуть исследования к созданию лучших систем. И это сработало.
Индустрия отреагировала, хотя, возможно, более прагматично, чем надеялись когнитивные ученые. Вместо «общего интеллекта» мы получили специализированные машины рассуждений, которые решают головоломки через итерационные циклы и генерацию кода.
С ARC-AGI-1 фактически насыщенным, даже более жесткий ARC-AGI-2 теперь падает. Система Poetiq превзошла человеческий средний показатель, несмотря на то, что никогда не обучалась на этих конкретных задачах.
Эффективность как катализатор прогресса
Эффективность улучшается вместе с производительностью. Согласно Poetiq, ее система «Poetiq (GPT-OSS-b)», основанная на открытой модели GPT-OSS-120B, достигает точности свыше 40% на ARC-AGI-1 менее чем за цент за задачу. Эпоха решений ARC, требующих огромных вычислений, подходит к концу, тенденция, которая дополнительно поддерживается «Tiny Recursive Model» без LLM.
ARC-AGI переживает типичный жизненный цикл бенчмарка: он становится метрикой для маркетинговых отделов. Как только цель определена и существуют стимулы, такие как миллионный приз ARC Prize, лаборатории будут оптимизировать, пока не достигнут числа.
Это не означает, что ИИ думает как человек. Это демонстрирует адаптивность современного исследования ИИ, которое может достичь почти любой абстрактной цели, комбинируя вычисления, синтетические данные и сложные методы поиска.
ARC-AGI-1 и ARC-AGI-2 преуспели, заставив сосредоточиться на рассуждениях и адаптации. То, что их теперь «решают», является не провалом теста, а доказательством его эффективности в стимулировании развития.





