
RAG-MCP: как решить проблему выбора инструментов в языковых моделях
Когда языковые модели получают доступ к сотням инструментов через MCP (Model Context Protocol), возникает парадокс: больше возможностей не всегда означает лучшую производительность. Проблема контекстного распада становится реальным вызовом для промышленного внедрения ИИ-агентов.
Проблема избыточного контекста
В мире MCP языковая модель теоретически может получить доступ к бесконечному количеству инструментов. Конечно, это преувеличение, но по мере роста количества доступных функций, API и интеграций возникает новая проблема — как модель понимает, какой инструмент использовать?
Когда каждая функция, API или интеграция помещается в единый промпт, модели сталкиваются с проблемой контекстного распада — ситуацией, когда переполнение контекстного окна модели слишком большим объемом информации фактически ухудшает рассуждения. Функции начинают сливаться, и даже продвинутые модели с трудом выбирают правильную или эффективно рассуждают о том, когда её использовать.
Деннис Томпсон писал об этих же проблемах в своем недавнем посте, «Избежание контекстного распада и улучшение точности инструментов для ИИ-агентов с использованием MCP». Он затронул ключевую проблему контекстного распада, но это также часть более широкой картины — того, как мы управляем и структурируем сам контекст.
В своем посте Деннис выделил три основных препятствия в построении корпоративного MCP Gateway от WRITER:
- Как предоставить агенту сотни инструментов без ручного создания каждого описания
- Как обеспечить, чтобы LLM находила и использовала правильный инструмент
- Как убедиться, что эти инструменты не раздувают контекстное окно
Архитектура MCP Gateway от WRITER решает эту проблему, действуя как контрольный слой, который автоматически поглощает API через OpenAPI или Postman, переписывает описания инструментов с использованием Palmyra X5 для ясности LLM и применяет векторный поиск для ранжирования и дистилляции сотен гранулярных конечных точек в небольшой набор «мета-инструментов».
Инженерия контекста: системный подход
По своей сути инженерия контекста — это системная дисциплина — то, как мы структурируем, извлекаем и управляем информацией, чтобы LLM могли эффективно рассуждать. Она охватывает несколько пересекающихся дисциплин — RAG, память, состояние, историю, промпт-инженерию и структурированные выходы — все они работают вместе, чтобы решить, какой контекст модель должна видеть, игнорировать или повторно использовать в состоянии, хранилище и контексте выполнения.
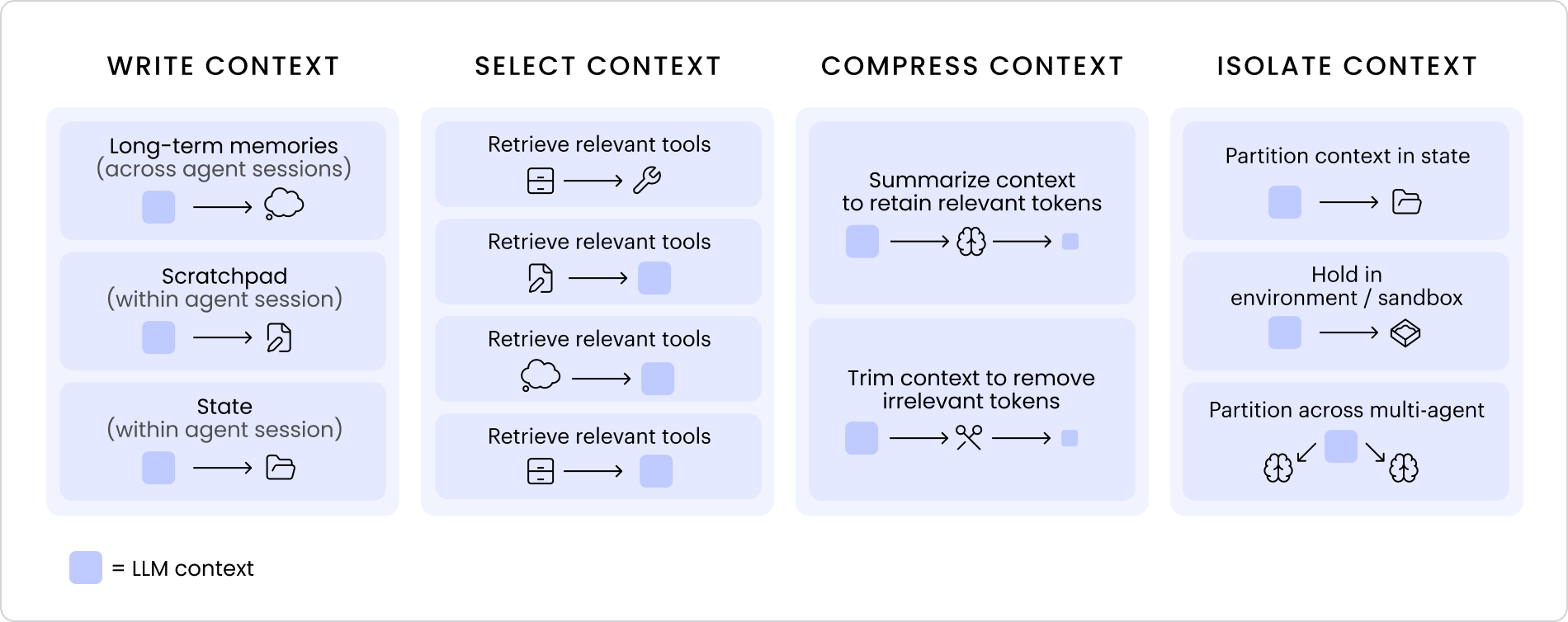
Если промпт-инженерия была сосредоточена на создании лучших входных данных, то инженерия контекста — это проектирование лучших систем для предоставления модели правильного контекста в нужное время. На практике это обычно сводится к четырем ключевым действиям — запись, выбор, сжатие и изоляция.
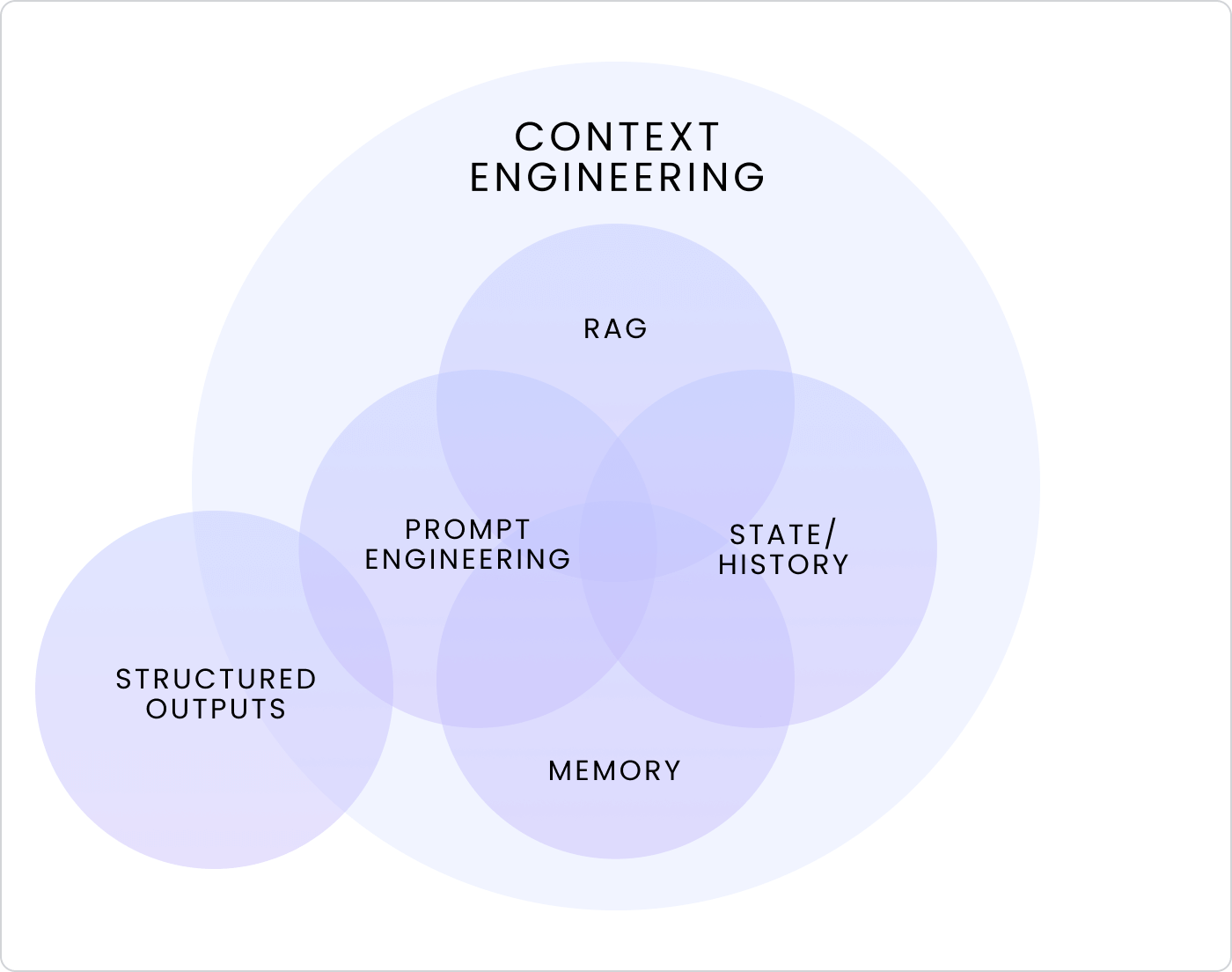
Вместе они формируют основу инженерии контекста, каждый подход важен для решения проблемы контекстного распада:
- Запись: сохранение релевантного контекста за пределами окна
- Выбор: извлечение наиболее релевантной информации
- Сжатие: сохранение только необходимого
- Изоляция: разделение контекста для фокусировки
Эти шаги предоставляют ментальную модель того, как сложные агентные системы могут оставаться надежными при масштабировании.
RAG-MCP: семантический поиск инструментов
Один из подходов к инженерии контекста для вызова инструментов — использование поисковых фреймворков, таких как RAG-MCP, которые переносят обнаружение инструментов на семантический поиск для идентификации наиболее релевантных инструментов для данного запроса из внешнего индекса перед передачей в LLM. Вместо загрузки каждого возможного инструмента в контекст модели, RAG-MCP вводит слой извлечения, который выбирает, сжимает и изолирует только то, что релевантно в данный момент.
Цель состоит не в том, чтобы дать моделям больше инструментов, а в том, чтобы помочь им извлекать и рассуждать с правильными в нужное время, переосмысливая то, как мы даем LLM правильный контекст для эффективного выполнения их задач.
Мы можем разбить RAG-MCP на три основных этапа извлечения:
- Векторизация и поиск: представление как запроса, так и всех описаний инструментов в общем векторном пространстве
- Ранжирование и выбор: оценка инструментов по семантическому расстоянию и возврат наиболее подходящих
- Внедрение и рассуждение: передача выбранных инструментов в контекст LLM для принятия решения о вызове
Чтобы визуализировать этот процесс, я создал упрощенную диаграмму, показывающую RAG-MCP на базовом уровне.
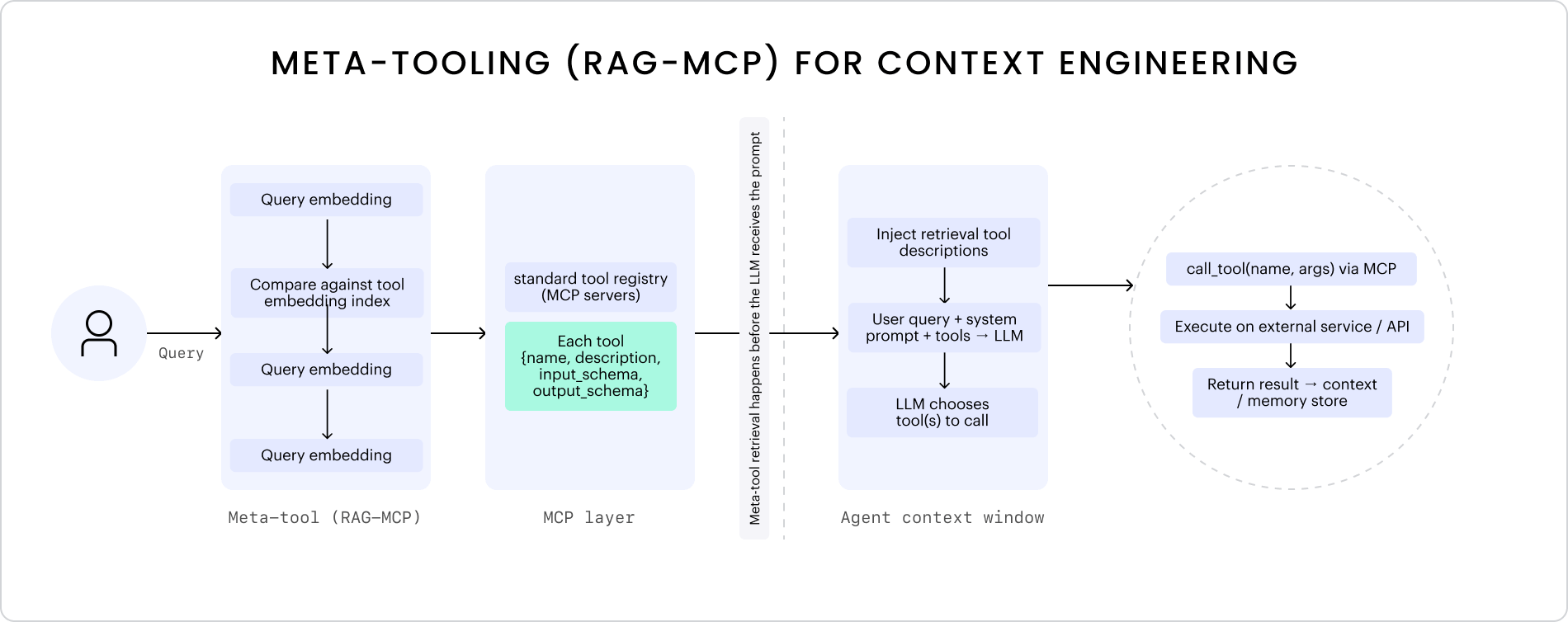
В статье о RAG-MCP этот подход более чем втрое повышает точность выбора инструментов и сокращает количество токенов в промпте более чем на 50%, делая модели более эффективными и надежными при рассуждениях с большими наборами инструментов. Это яркий пример того, как инженерия контекста помогает избежать раздувания промптов, разделяя извлечение и рассуждение.
Vы десятилетиями боролись с проблемой «перегрузки выбором» в пользовательских интерфейсах, а теперь столкнулись с её точной копией в мире ИИ. RAG-MCP — это элегантное решение, которое превращает проблему масштабирования в преимущество: вместо того чтобы заваливать модель всеми инструментами сразу, мы даём ей умную систему навигации. Это как разница между поиском книги в библиотеке с каталогом и поиском её методом случайного перебора полок.
Прототип RAG-MCP на практике
Чтобы исследовать эти идеи на практике, рассмотрим упрощенный прототип RAG-MCP с использованием sentence-transformers для слоя извлечения. Цель состоит в том, чтобы представить каждый инструмент MCP в общем векторном пространстве, извлечь наиболее семантически релевантные для данного запроса и внедрить только эти инструменты в контекст модели перед рассуждением.
"""
RAG-MCP: Retrieval-Augmented Generation with MCP
Lightweight prototype demonstrating the core retrieval and injection flow.
"""
import asyncio
from typing import List, Dict, Any
import httpx
import numpy as np
from sentence_transformers import SentenceTransformer, util
# Configuration
DEFAULT_MCP_ENDPOINT = "<your_mcp_server_endpoint>" # e.g. http://localhost:3000
class RAGMCP:
"""Core RAG-MCP steps:
1. Index tools with embeddings
2. Rank tools by semantic similarity
3. Inject relevant tools into context
"""
def __init__(self, mcp_endpoint: str, embedding_model: str = "all-MiniLM-L6-v2"):
self.mcp_endpoint = mcp_endpoint
self.embedding_model = SentenceTransformer(embedding_model)
self.tool_embeddings: List[np.ndarray] = []
self.tools: List[Dict[str, Any]] = []
async def initialize_tool_registry(self):
"""Step 1: Fetch MCP tools and index them with embeddings"""
async with httpx.AsyncClient() as client:
response = await client.post(
self.mcp_endpoint,
json={"jsonrpc": "2.0", "id": 1, "method": "tools/list", "params": {}},
headers={"Content-Type": "application/json"},
)
self.tools = response.json()["result"]["tools"]
tool_texts = [f"{t['name']}: {t['description']}" for t in self.tools]
self.tool_embeddings = self.embedding_model.encode(tool_texts)
def retrieve_tools(self, query: str, top_k: int = 3) -> List[Dict[str, Any]]:
"""Step 2: Rank tools by semantic similarity"""
query_emb = self.embedding_model.encode([query])
similarities = util.cos_sim(query_emb, self.tool_embeddings)[0]
top_indices = similarities.argsort(descending=True)[:top_k]
return [
{**self.tools[i], "similarity_score": similarities[i].item()}
for i in top_indices
]
def build_prompt_with_tools(self, tools: List[Dict[str, Any]], query: str) -> str:
"""Step 3: Inject relevant tools into the model's context"""
tool_descriptions = [
f"- {t['name']}: {t['description']} (similarity: {t['similarity_score']:.3f})"
for t in tools
]
return f"""
Available tools:
{chr(10).join(tool_descriptions)}
Query: {query}
Please respond with either:
1. A direct answer if no tool is needed
2. A tool call in the format:
{{"tool_call": {{"name": "tool_name", "arguments": {{...}}}}}}
"""
# Example usage
async def main():
rag_mcp = RAGMCP(DEFAULT_MCP_ENDPOINT)
await rag_mcp.initialize_tool_registry()
query = "Add a file to the marketing Knowledge Graph"
tools = rag_mcp.retrieve_tools(query)
print(rag_mcp.build_prompt_with_tools(tools, query))
if __name__ == "__main__":
asyncio.run(main())
Этот прототип демонстрирует, как RAG-MCP решает фундаментальную проблему масштабирования инструментов в агентных системах. Вместо того чтобы заваливать модель сотнями описаний функций, система семантически выбирает только релевантные, значительно сокращая контекст и улучшая точность.
По материалам Writer.



