Google разработала метод вложенного обучения, чтобы решить проблему забывания у LLM
Исследователи Google представили метод «вложенного обучения», который может решить одну из фундаментальных проблем современных языковых моделей — катастрофическое забывание. Эта технология позволяет ИИ сохранять долговременные воспоминания после обучения и постоянно обновлять знания без потери уже усвоенной информации.
Проблема статичности языковых моделей
В своей статье для конференции NeurIPS 2025 специалисты Google Research подчеркивают ключевую проблему: крупные языковые модели не могут формировать новые долговременные воспоминания после завершения обучения. После тренировки эти модели сохраняют только то, что находится в их текущем контекстном окне или было усвоено во время предварительного обучения.
Расширение контекстного окна или повторное обучение лишь откладывает проблему — это похоже на лечение амнезии с помощью большего блокнота для записей. Современные модели в основном остаются статичными после предварительного обучения. Они могут выполнять изученные задачи, но не способны приобретать новые навыки за пределами своего контекста, что приводит к катастрофическому забыванию. Чем больше обновлений получает модель, тем хуже становится эта проблема.
Нейробиологическое вдохновение
Как и многие достижения машинного обучения, вложенное обучение черпает идеи из нейробиологии. Мозг работает на разных скоростях: быстрые цепи обрабатывают настоящее, а более медленные консолидируют важные паттерны в долговременную память.
Большинство переживаний быстро забывается; лишь немногие становятся устойчивыми воспоминаниями благодаря нейропластичности — способности мозга перестраивать себя, сохраняя при этом существенную информацию. Авторы противопоставляют это современным языковым моделям, чьи знания ограничены их контекстным окном или статичным предварительным обучением.

Вложенное обучение группирует компоненты модели по частоте их обновления, используя мозговые волны как метафору. Такая многоуровневая организация памяти позволяет модели усваивать новую информацию без перезаписи уже существующих знаний.
Вложенное обучение рассматривает каждую часть модели ИИ — включая оптимизатор и алгоритм обучения — как память. Обратное распространение хранит связи между данными и ошибками, а состояние оптимизатора, такое как импульс, также действует как память. Система непрерывной памяти (Continuum Memory System, CMS) разделяет память на модули, которые обновляются с разной скоростью, придавая модели временную глубину.
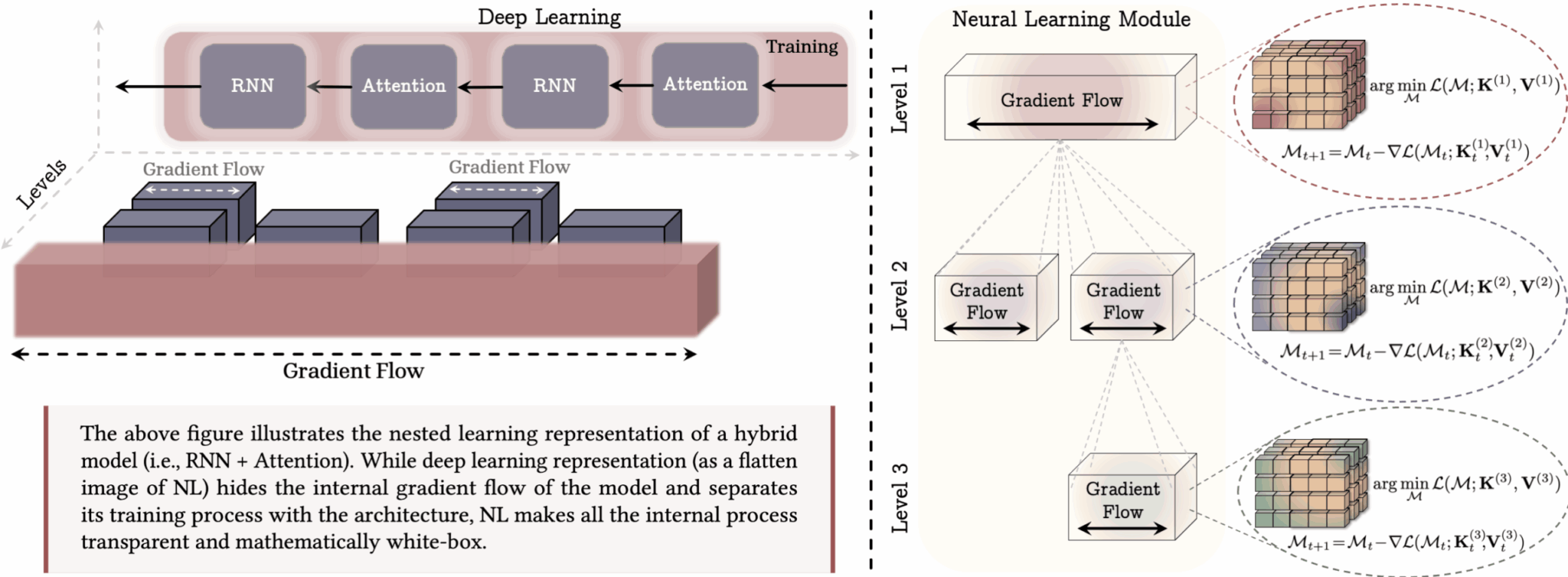
Вложенное обучение разбивает процесс на слои, каждый со своим потоком градиентов и целью. На примере показана модель с тремя слоями.
Архитектура HOPE в действии
Архитектура HOPE от Google реализует этот подход на практике. HOPE использует модули долговременной памяти под названием Titans, которые хранят информацию на основе того, насколько она удивительна для модели. Она наслаивает различные типы памяти и использует блоки CMS для более крупных контекстных окон.
- Быстрые слои обрабатывают живой ввод
- Более медленные слои отбирают важное для долговременного хранения
- Система может адаптировать свои правила обновления по мере обучения
Этот подход выходит за рамки типичной модели «предварительное обучение и заморозка».
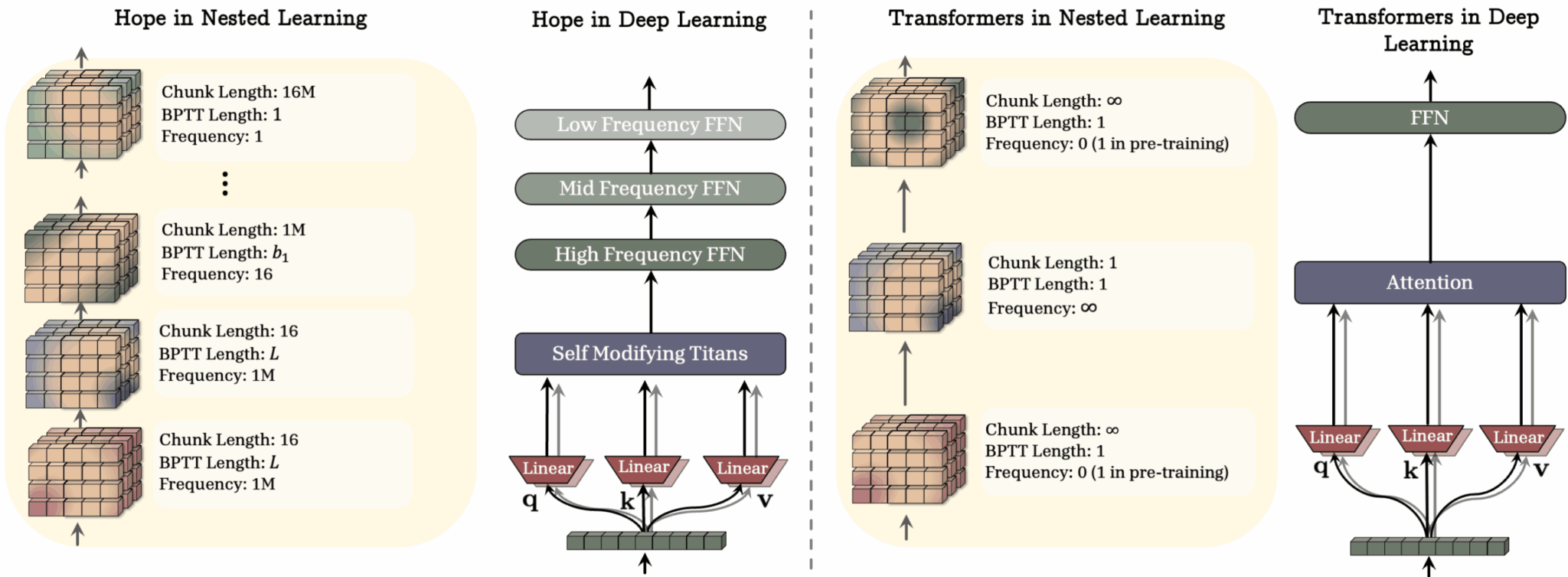
HOPE разделяет модель на слои с разными размерами фрагментов и скоростями обновления, что позволяет ей обрабатывать новую и старую информацию с разной скоростью. Стандартные трансформеры работают только с текущим контекстным окном или данными из предварительного обучения.
Результаты тестирования
Команда протестировала HOPE на задачах языкового моделирования и рассуждения. При использовании моделей с 1,3 миллиарда параметров, обученных на 100 миллиардах токенов, HOPE превзошла Transformer++ и более новые модели, такие как RetNet и DeltaNet.
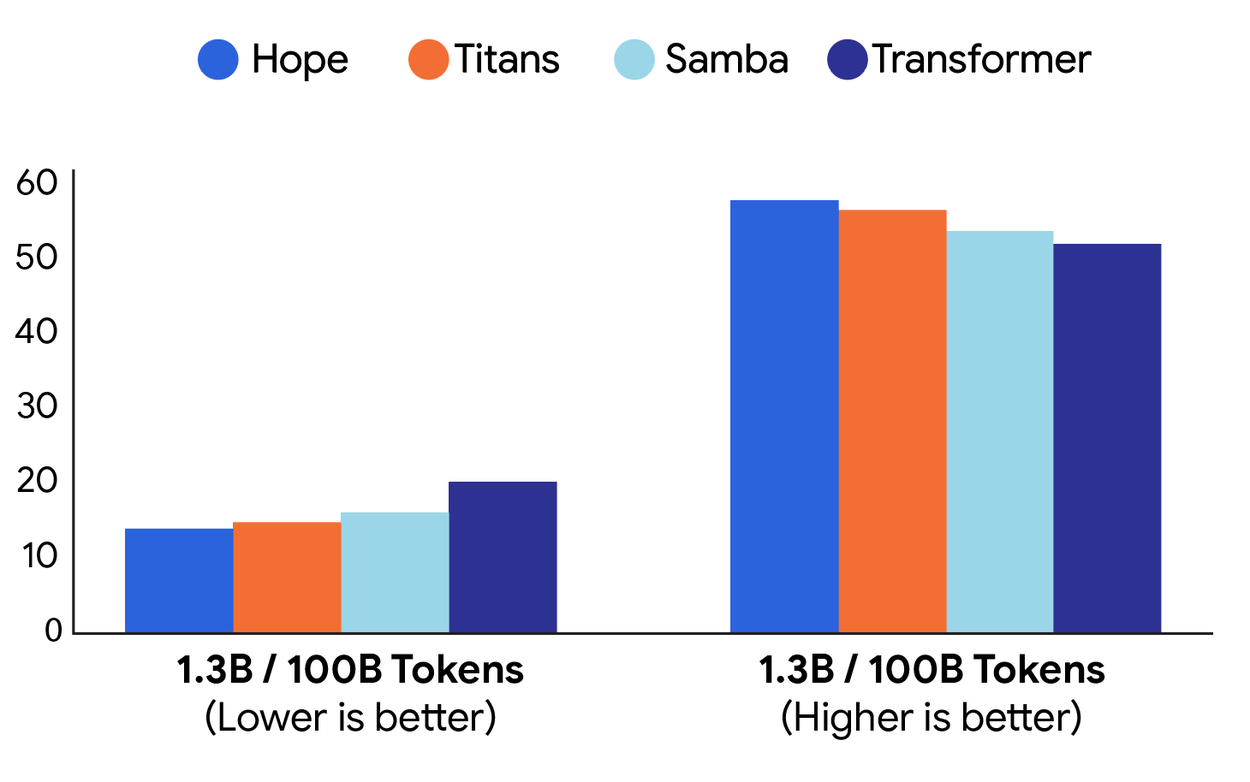
HOPE демонстрирует наименьшие потери и самые высокие результаты в бенчмарках по сравнению с другими моделями, хотя разница невелика.
HOPE также показала лучшие результаты в тестах с длинным контекстом и поиске иголки в стоге сена, где модель должна найти что-то конкретное в большом объеме текста. Тесты проводились на моделях от 340 миллионов до 1,3 миллиарда параметров. Преимущества HOPE были последовательными, и авторы утверждают, что она может превзойти как трансформеры, так и современные рекуррентные сети.
Подход Google к вложенному обучению выглядит многообещающим решением одной из самых раздражающих проблем современных LLM — их неспособности к настоящему непрерывному обучению. Вместо того чтобы просто увеличивать размер контекстного окна, они предлагают архитектурное решение, которое имитирует работу человеческой памяти. Интересно, что это может означать для будущего персонализированных ассистентов — представьте себе ИИ, который действительно помнит ваши предпочтения и стиль общения, а не просто имитирует это через промпты. Хотя преимущества пока скромные, сам подход открывает путь к созданию по-настоящему адаптивных систем.
По материалам The Decoder.