
ИИ до сих пор не умеет решать сложные задачи для научных исследований по физике
Новый бенчмарк CritPt демонстрирует, что даже самые продвинутые языковые модели не могут справиться с реальными исследовательскими задачами в физике. Разработанный для проверки способности ИИ помогать ученым в прорывных исследованиях, тест включает оригинальные, неопубликованные задачи уровня аспиранта, начинающего самостоятельный проект.
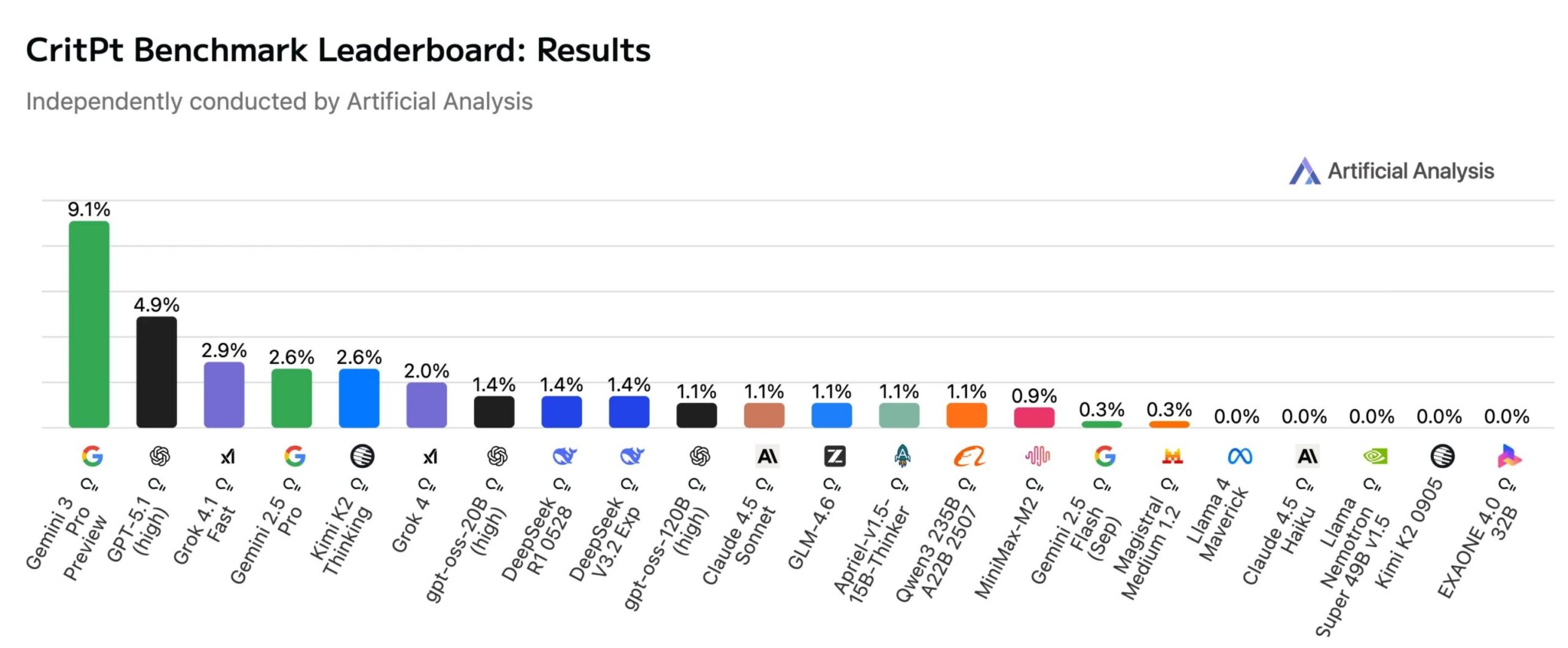
Результаты оказались разочаровывающими. По данным независимой оценки Artificial Analysis, модель Google Gemini 3 Pro Preview показала точность всего 9,1%, в то время как GPT-5.1 (high) от OpenAI занял второе место с 4,9% точности. Примечательно, что Gemini достиг этого результата, используя на 10% меньше токенов.
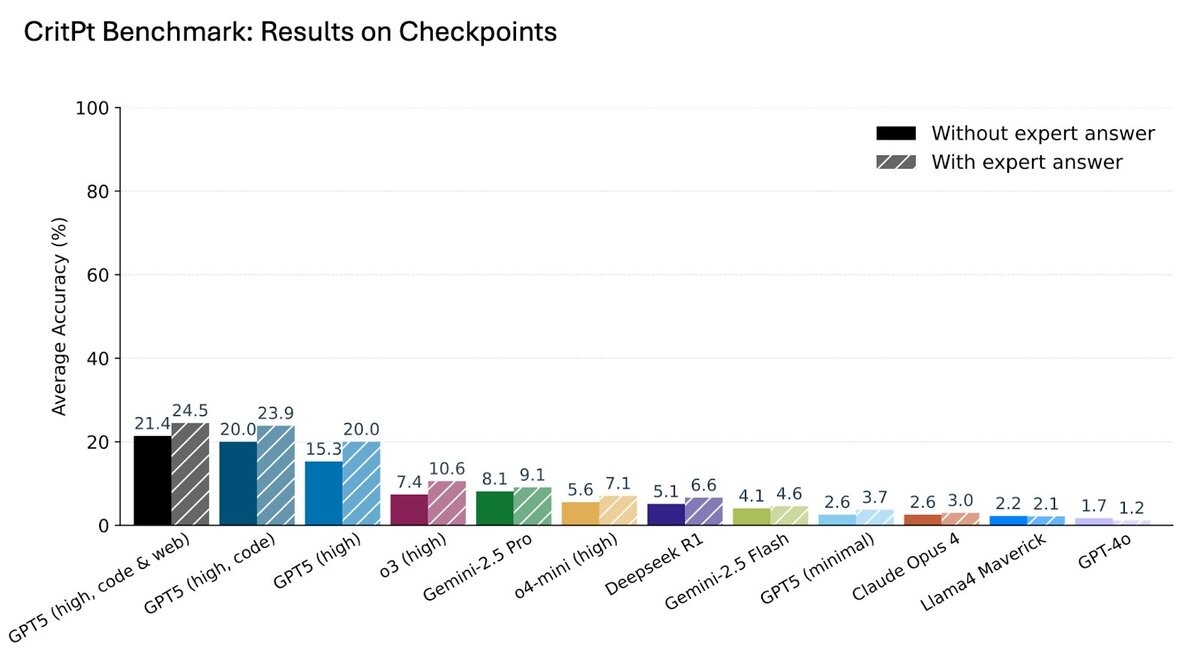
Пределы возможностей современных ИИ
Бенчмарк CritPt включает 71 полноценную исследовательскую задачу из одиннадцати областей физики: квантовая физика, астрофизика, физика высоких энергий, биофизика и другие. Для предотвращения угадывания или поиска в базе знаний все задачи основаны на неопубликованных материалах. Каждая проблема была разбита на 190 меньших «чекпойнтов» для измерения частичного прогресса.
Исследование показывает: современные большие языковые модели не обладают строгостью, креативностью и точностью, необходимыми для самостоятельного решения открытых физических проблем. Однако на более простых, четко определенных подзадачах модели демонстрируют измеримый прогресс, что указывает на их потенциальную полезность в роли ассистентов.
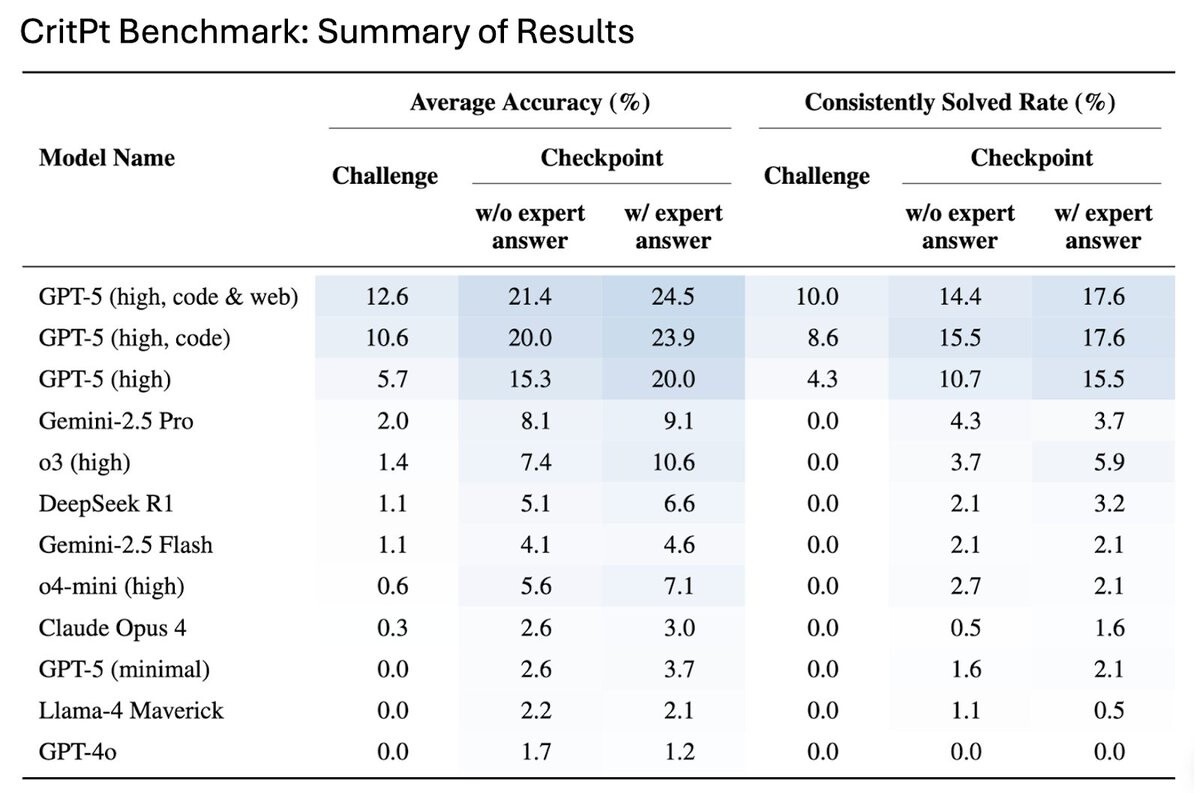
Проблема стабильности решений
Команда также проверила стабильность работы моделей с использованием более строгого показателя — «стабильной точности решения», требующего от модели давать правильный ответ четыре раза из пяти. При таком требовании производительность резко падает во всех случаях, что демонстрирует хрупкость рассуждений моделей даже на задачах, которые они иногда решают.
Эта недостаточная стабильность создает серьезные проблемы для исследовательских процессов. Модели часто производят ответы, которые выглядят убедительно, но содержат тонкие ошибки, сложные для обнаружения, что может легко ввести исследователей в заблуждение и потребовать трудоемкой экспертной проверки.
Текущие результаты напоминают нам о фундаментальном ограничении современных ИИ: они великолепны в интерполяции известного, но беспомощны перед действительно новыми проблемами. Девять процентов точности — это не «почти успех», а демонстрация того, что до реального научного прорыва еще очень далеко. Пока что ИИ остается дорогим стажером, который умеет красиво оформлять отчеты, но не способен к настоящему научному открытию.
Исследователи утверждают, что в обозримом будущем более реалистичной целью является не «ИИ-ученый», заменяющий человеческих экспертов, а «исследовательский ассистент», автоматизирующий определенные этапы рабочего процесса. Это соответствует текущим отраслевым планам: OpenAI планирует выпустить систему исследовательского интерна к сентябрю 2026 года и полностью автономного исследователя к марту 2028 года. Компания утверждает, что GPT-5 уже экономит время исследователей.
По материалам The Decoder.



