
Модель NeuTTS-air синтезирует речь в 200 раз быстрее реального времени на одной видеокарте
Инженер-исследователь представил метод оптимизации модели синтеза речи NeuTTS-air, позволяющий генерировать более 200 секунд аудио за одну секунду на одной видеокарте GeForce RTX 4070 Ti Super.
Проблема производительности
NeuTTS-air — это модель преобразования текста в речь с 0.5 миллиардами параметров, способная создавать реалистичную и эмоциональную речь, а также клонировать голоса. Несмотря на относительно небольшие размеры, модель изначально работала довольно медленно на графических процессорах при использовании стандартной библиотеки transformers.
Оптимизация языковой модели
Поскольку языковая модель в NeuTTS-air основана на стандартной архитектуре Qwen2LM, для её ускорения использовалась высокооптимизированная библиотека LMdeploy. Выбор именно этого инструмента был обусловлен несколькими ключевыми преимуществами:
- Простая установка без конфликтов зависимостей
- Полная совместимость с Windows без потери производительности
- Экстремально низкая задержка — менее 50 мс
- Скорость работы, превосходящая vLLM и сопоставимая с SGLang/TensorRT-LLM
Дополнительные техники оптимизации
Для дальнейшего повышения производительности были применены продвинутые методы LMdeploy, включая кэширование префиксов и int8 кэш. Кэширование префиксов значительно улучшило скорость пакетной обработки ценой некоторого увеличения задержки, что делает его отключение предпочтительным для потоковой обработки.
Int8 кэш также помог в пакетной обработке, сохраняя контекст в int8 вместо bf16, что экономит видеопамять с минимальной потерей качества.
Важное ограничение: NeuTTS-air не работает в float16 и поддерживает только bfloat16 или float32, что делает её несовместимой с GPU ниже архитектуры Ampere (T4/20xx серии).
Оптимизация нейрального кодера
NeuTTS-air поддерживает два варианта кодеков: базовый neucodec и оптимизированный neucodec-distill. Архитектура кодеков включает:
- Семантический энкодер wav2vec2 для кодирования «смысла» аудио
- Акустический энкодер BigCodec для кодирования акустической информации
- Декодер Vocos для преобразования токенов обратно в аудио
Ключевое отличие neucodec от аналогичного xcodec2 — вывод аудио с частотой 24 кГц вместо 16 кГц.
Distill-neucodec использует более быстрые энкодеры: SQCodec вместо BigCodec и DistillHubert вместо wav2vec2, что значительно ускоряет кодирование.
Архитектура Distill NeuCodec:
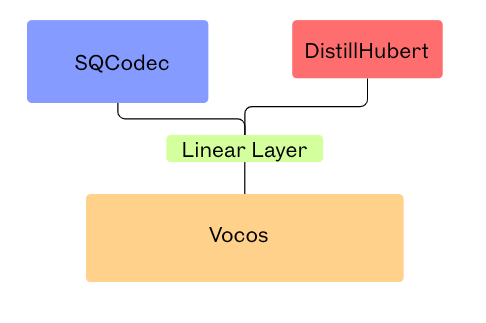
Дальнейшая оптимизация кодера
При генерации минутных аудиозаписей neucodec становился узким местом вместо языковой модели. Для решения этой проблемы все сгенерированные токены были разделены на группы по 50 и обрабатывались пакетно, что увеличило скорость декодирования с 400x до 800x относительно реального времени.
Полная архитектура:
Финальный результат — ускорение в 211 раз относительно реального времени при использовании тестового файла из репозитория.
Достижение 200-кратного ускорения на относительно скромном оборудовании — впечатляющий результат, особенно учитывая сохранение качества синтеза. Интересно, что основным узким местом оказался не LLM, а нейральный кодер — это показывает, насколько важна оптимизация всех компонентов пайплайна. Техника пакетной обработки токенов выглядит элегантным решением проблемы масштабирования.
Планы по развитию
Среди перспективных направлений для дальнейшего развития:
- Многоязычные модели (уже доступны для хинди, французского, голландского, испанского)
- Мультиспикерские модели для генерации речи в формате подкастов
- Онлайн потоковый вывод с задержкой 100 мс и поддержкой множества одновременных пользователей
Исходный код доступен в репозитории проекта.
По материалам HuggingFace.




