
Языковые модели научились рассуждать на языке пользователя без потери точности
Исследователи из HuggingFace представили метод, который позволяет языковым моделям сохранять точность при переходе на рассуждения на языке пользователя. Технология решает проблему «внутреннего английского» в моделях, когда они понимают запрос на одном языке, но мыслят на другом.
Проблема языкового переключения в рассуждениях
Когда вы задаете языковой модели математическую задачу на японском, она может вежливо ответить на японском, но при этом внутренние рассуждения будут происходить на английском или китайском. Переменные, шаги решения и математические леммы часто незаметно переключают язык во время цепочек рассуждений.
Такое поведение, когда модели по умолчанию используют английский для chain-of-thought рассуждений, — это больше чем просто любопытство. Оно нарушает следование инструкциям, сбивает с толку человеческих наблюдателей и подрывает цель мультиязычной оценки.
Двухэтапное решение
Исследователи использовали модель deepseek-ai/DeepSeek-R1-Distill-Qwen-7B и разработали двухэтапный подход:
- Этап 1 — небольшое обучение с учителем: тонкая настройка на 817 мультиязычных цепочках рассуждений из набора LiMO
- Этап 2 — обучение с подкреплением: применение GRPO только на математических задачах, переведенных на каждый язык
Ключевая идея заключалась в том, чтобы позволить RL оптимизировать сложные случаи и поведение проверки, в то время как высокий порог отсечения предотвращает катастрофический коллапс стиля рассуждений обратно к английскому.
Результаты и эффективность
Метод тестировался на трех языках — японском, французском и испанском — на различных наборах данных: MMLU College Math, AIME25, GPQA и MMLU Pro Medicine.
Удивительно, но всего 817 примеров оказалось достаточно, чтобы повысить языковую согласованность почти до потолка — ~99-100% для французского и испанского и значительно улучшить для японского.
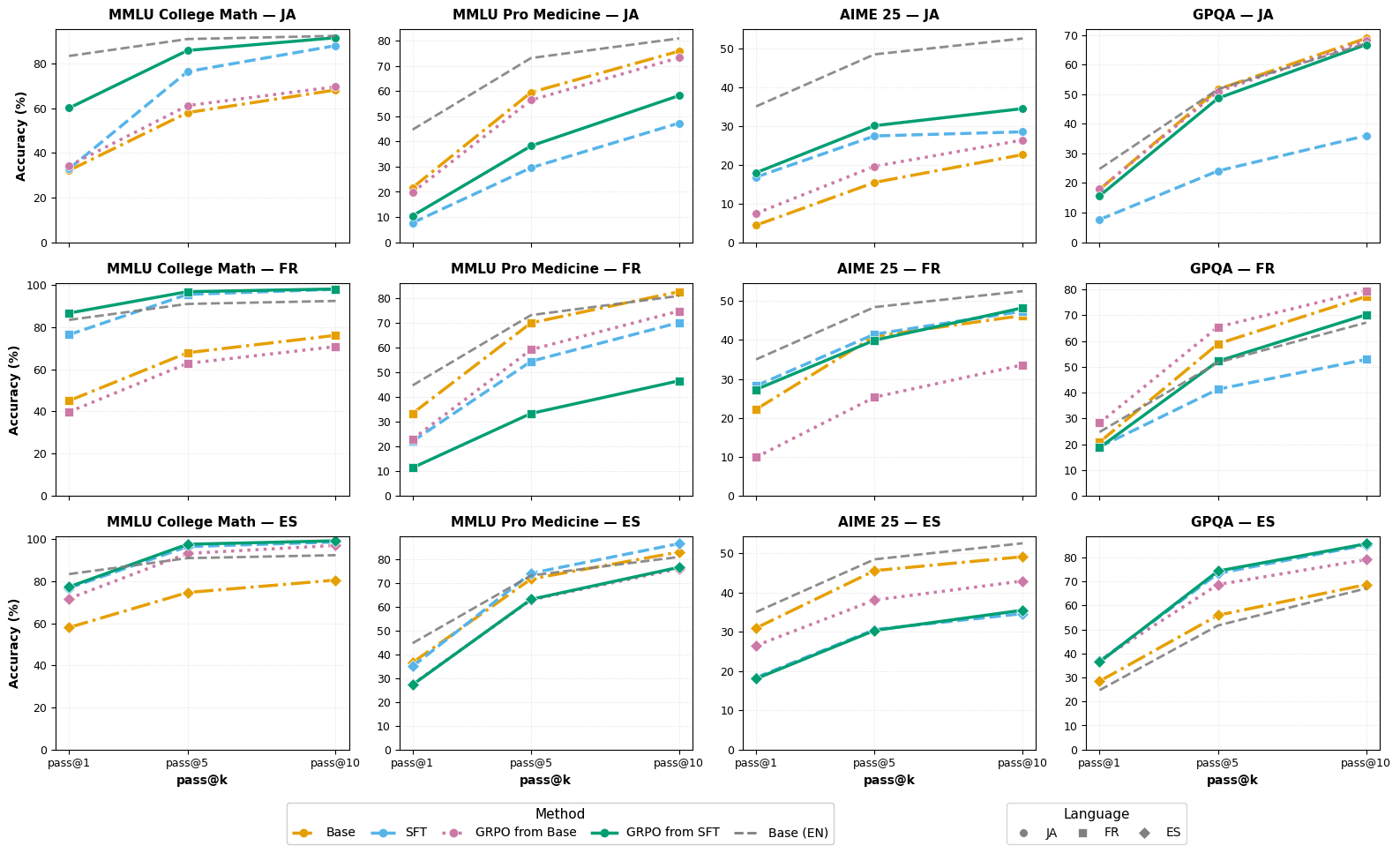
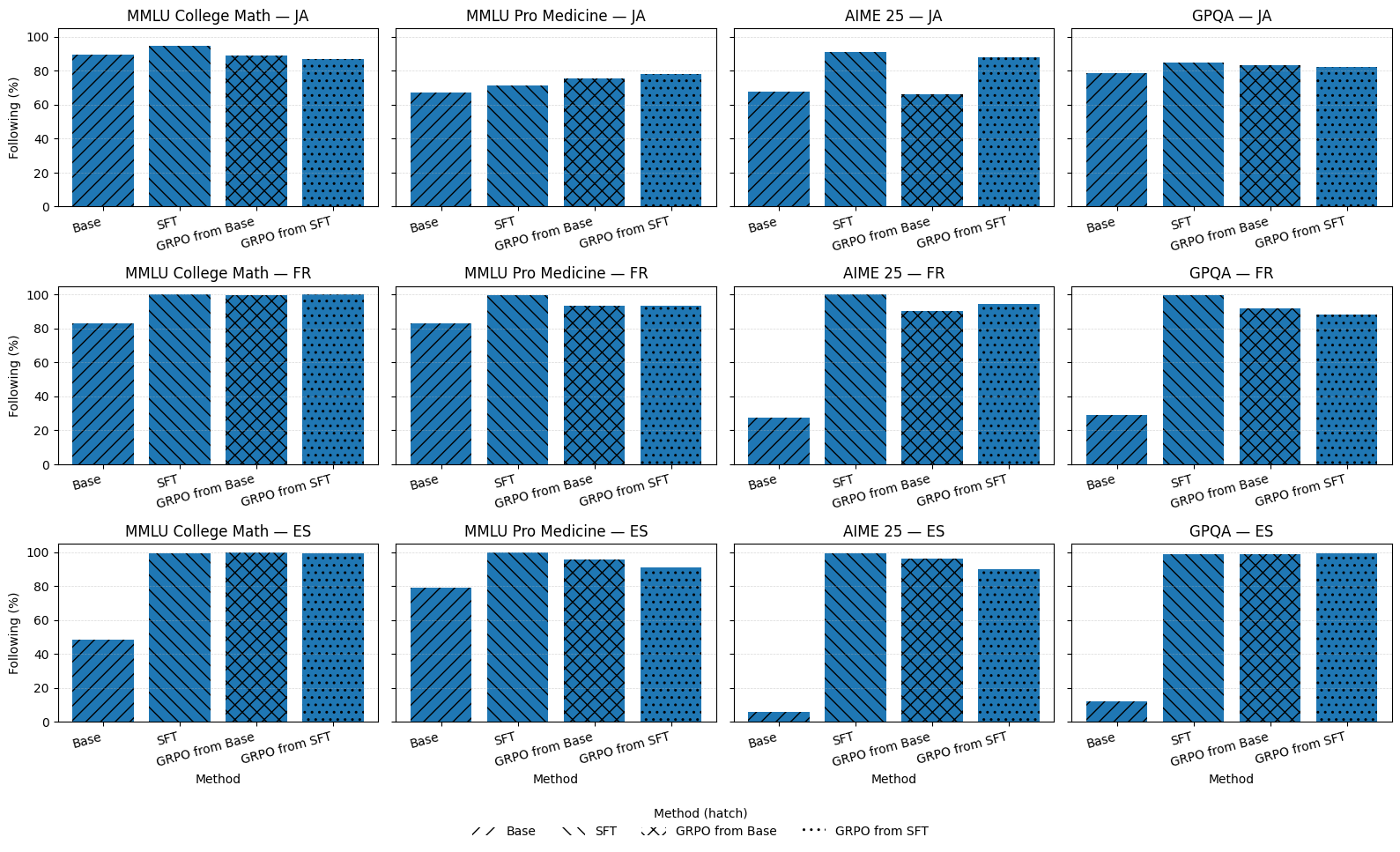
Похоже, мы наконец-то нашли способ заставить модели «думать» на том же языке, на котором их спрашивают, не превращая их при этом в математических неудачников. Особенно впечатляет, что для переучивания потребовалось всего 817 примеров — словно перепрограммировали внутренний монолог модели микрочипом вместо молотка. Интересно, сколько еще таких «скрытых переключателей» можно найти в больших языковых моделях.
Практические последствия
Исследование показывает, что небольшая мультиязычная SFT — это наиболее экономически эффективный способ «направить» цепочки рассуждений на языке пользователя. Добавление математического GRPO затем восстанавливает или улучшает точность на сложных наборах типа AIME и GPQA, в основном сохраняя языковую дисциплину SFT.
Код и данные доступны в открытом доступе:
Это исследование открывает путь к созданию по-настоящему мультиязычных AI-ассистентов, которые не просто отвечают на языке пользователя, но и мыслят на нем, что особенно важно для образовательных и экспертных систем.
По материалам HuggingFace.




