
Google Cloud представила виртуальные машины G4 для многопроцессорных GPU-вычислений
В облачной гонке за производительностью ИИ-инфраструктуры Google Cloud делает ставку на собственную технологию межпроцессорной коммуникации. Компания анонсировала общую доступность виртуальных машин G4 с GPU NVIDIA RTX PRO 6000 Blackwell Server Edition, но главное — уникальную программно-определяемую P2P-архитектуру, которая ускоряет коллективные операции в многопроцессорных конфигурациях.
Проблема производительности коллективных операций
Большие языковые модели значительно различаются по размеру: от небольших (~7B параметров) до средних (~70B) и крупных (~350B+). Даже с 96GB памяти GDDR7 на NVIDIA RTX PRO 6000 Blackwell многие модели не помещаются в один GPU. Решение — тензорный параллелизм (TP), распределяющий слои модели между несколькими GPU.
Однако ключевым узким местом становится необходимость объединения частичных результатов через коллективные операции типа All-Gather или All-Reduce. Именно здесь G4 демонстрирует преимущество благодаря запатентованной PCIe-архитектуре.
Как работает ускорение P2P в G4
Многопроцессорные конфигурации G4 получают значительно улучшенные PCIe P2P-возможности благодаря комбинации кастомного оборудования и программного обеспечения. Эта оптимизация напрямую ускоряет коллективные коммуникации, включая All-to-All, All-Reduce и All-Gather для обмена данными между GPU.
Результат — малолатентный путь передачи данных, обеспечивающий существенное повышение производительности для критически важных рабочих нагрузок, таких как многопроцессорный инференс и дообучение.
Фактически, для всех основных коллективных операций улучшенная P2P-способность G4 обеспечивает ускорение до 2.2x без каких-либо изменений в коде или рабочих нагрузках.
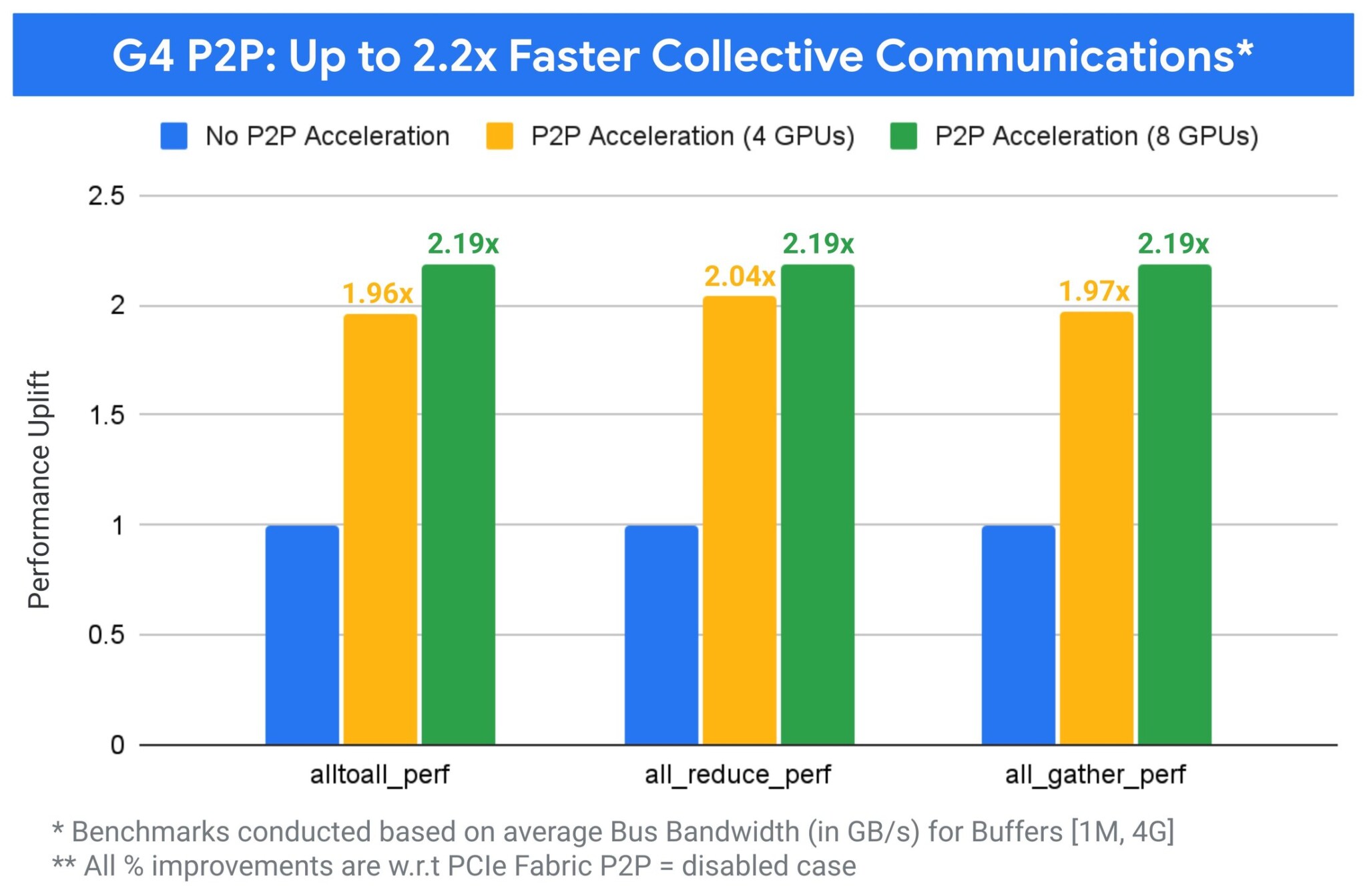
Производительность инференса с P2P на G4
На экземплярах G4 улучшенная peer-to-peer коммуникация напрямую повышает производительность многопроцессорных рабочих нагрузок, особенно для тензорного параллельного инференса с vLLM — с увеличением пропускной способности до 168% и снижением межтокенной задержки до 41%.
Эти улучшения особенно заметны при использовании тензорного параллелизма для обслуживания моделей по сравнению со стандартными предложениями без P2P.
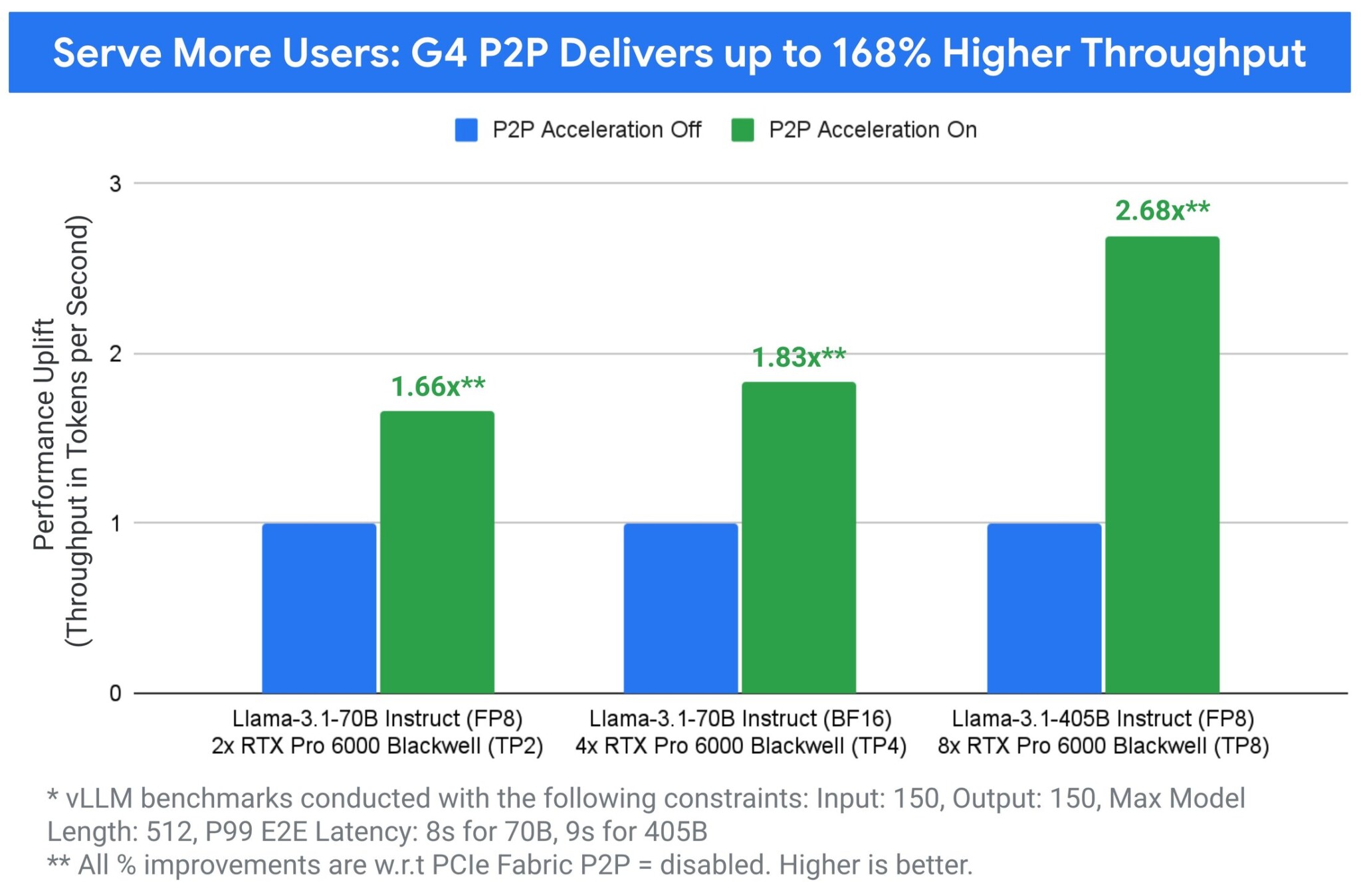
В то же время G4 в сочетании с программно-определяемым PCIe и инновациями P2P значительно повышает пропускную способность инференса и снижает задержку, предоставляя контроль для оптимизации развертывания инференса под бизнес-потребности.
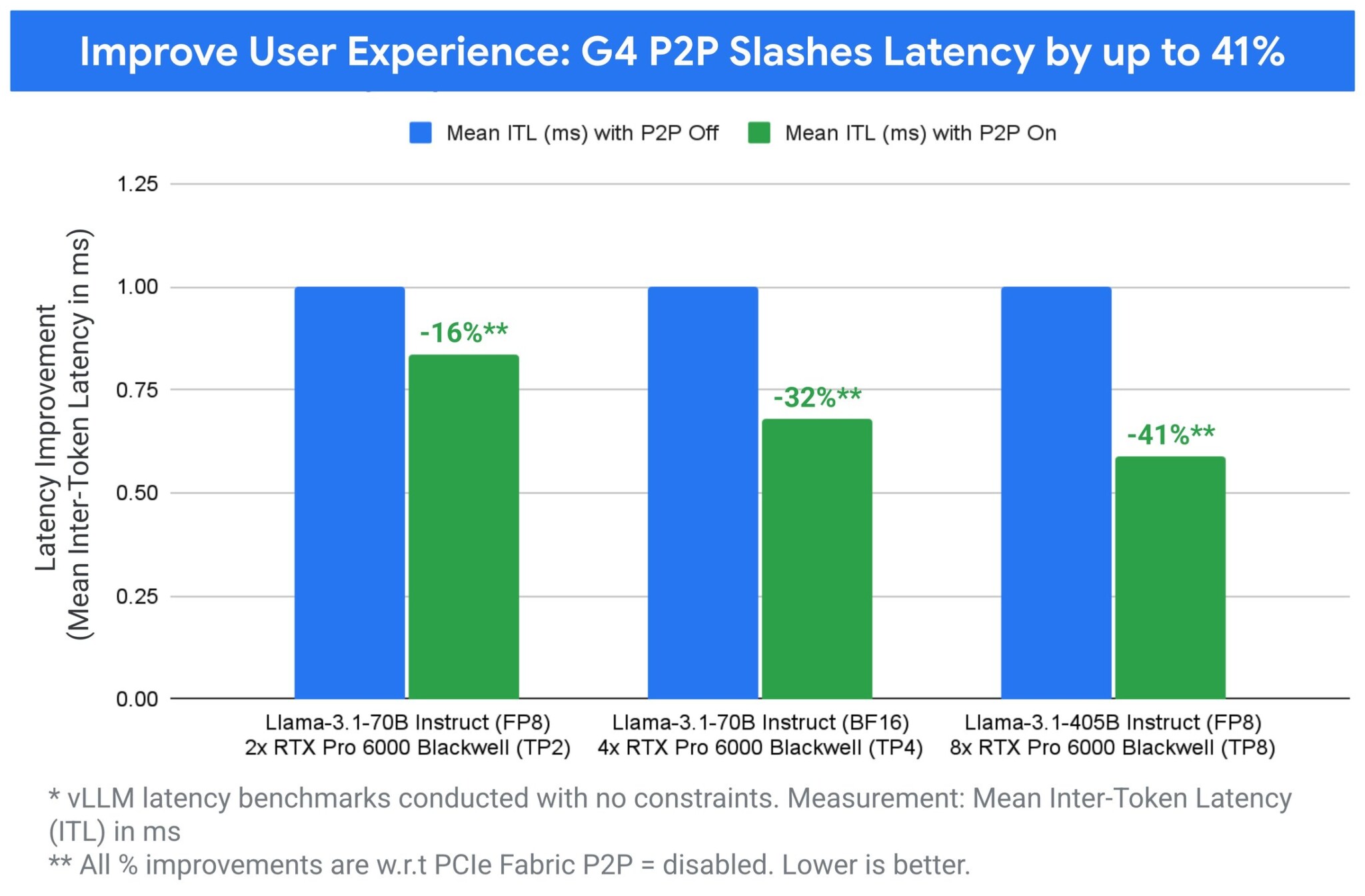
Пропускная способность или скорость: выбор за вами
Платформенные оптимизации на виртуальных машинах G4 напрямую превращаются в гибкое и мощное конкурентное преимущество. Для интерактивных генеративных ИИ-приложений, где пользовательский опыт имеет первостепенное значение, технология P2P G4 обеспечивает до 41% меньше межтокенной задержки — критической паузы между генерацией каждой части ответа.
Альтернативно, для рабочих нагрузок, где приоритетом является чистая пропускная способность, например пакетный инференс, G4 с P2P позволяет клиентам обслуживать до 168% больше запросов по сравнению с аналогичными предложениями.
Интересно наблюдать, как облачные провайдеры начинают конкурировать не только мощностью железа, но и эффективностью межпроцессорных коммуникаций. P2P-оптимизация на уровне платформы — это тот самый случай, когда программные инновации могут дать больше преимуществ, чем простое наращивание аппаратных характеристик. Особенно впечатляет заявленное ускорение коллективных операций до 2.2x без изменений в коде — это именно то, что нужно разработчикам: производительность без головной боли с рефакторингом.
Масштабирование с G4 и GKE Inference Gateway
Хотя P2P оптимизирует производительность для одной реплики модели, масштабирование для удовлетворения производственного спроса часто требует нескольких реплик. Здесь особенно ярко проявляет себя GKE Inference Gateway. Он действует как интеллектуальный диспетчер трафика для моделей, используя расширенные функции, такие как маршрутизация с учетом префикс-кеша и пользовательское планирование для максимизации пропускной способности и сокращения задержки во всем развертывании.
Объединяя вертикальное масштабирование P2P G4 с горизонтальным масштабированием Inference Gateway, можно построить сквозное решение для обслуживания, исключительно производительное и рентабельное для самых требовательных генеративных ИИ-приложений.
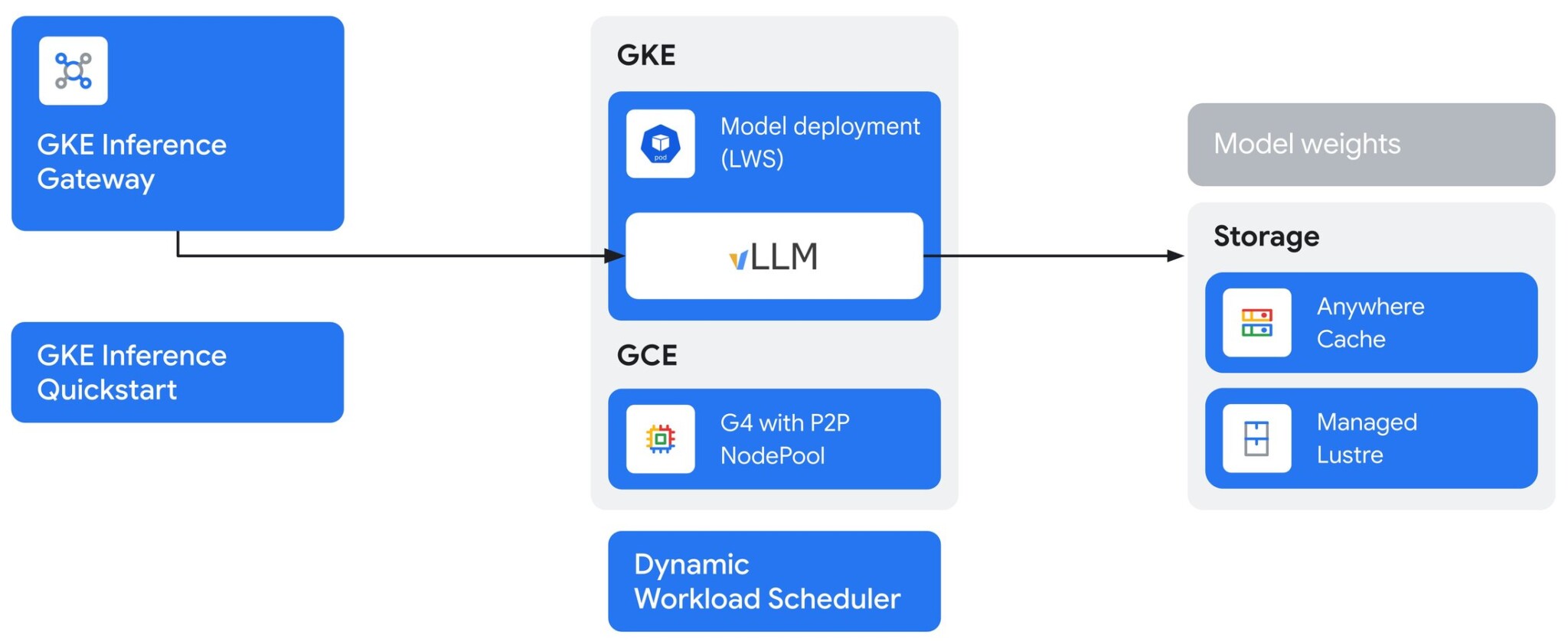
Поддерживаемые конфигурации G4 с P2P
Возможности peer-to-peer для NVIDIA RTX PRO 6000 Blackwell доступны со следующими многопроцессорными конфигурациями G4 VM:
| Тип машины | GPU | Peer-to-Peer | Память GPU (GB) | vCPU | Память хоста (GB) | Локальный SSD (GB) |
|---|---|---|---|---|---|---|
| g4-standard-96 | 2 | Да | 192 | 96 | 360 | 3,000 |
| g4-standard-192 | 4 | Да | 384 | 192 | 720 | 6,000 |
| g4-standard-384 | 8 | Да | 768 | 384 | 1,440 | 12,000 |
Для конфигураций VM меньше 8 GPU программно-определяемая PCIe-архитектура обеспечивает изоляцию путей между GPU, назначенными разным VM на одной физической машине. PCIe-пути создаются динамически при создании VM и зависят от формы VM, обеспечивая изоляцию на нескольких уровнях стека платформы для предотвращения коммуникации между GPU, не назначенными одной VM.
Сообщает Google Cloud Blog.




