
BigCodeArena запускает платформу для оценки моделей генерации кода через выполнение программ
Оценка качества кода, сгенерированного искусственным интеллектом, всегда была сложной задачей. В то время как человек может легко определить, выглядит ли код «правильно», проверка его работоспособности, обработки крайних случаев и получения ожидаемого результата требует запуска и тестирования. Именно поэтому сегодня мы представляем BigCodeArena — первую платформу с участием человека для оценки моделей генерации кода через выполнение.
Мотивация создания
Область генерации кода долгое время боролась с надежными методами оценки. Традиционные бенчмарки вроде HumanEval проверяют код против предопределенных тестовых случаев, но они представляют лишь крошечную долю реальных задач программирования. Платформы человеческой оценки существуют для общих чат-ботов, но они не подходят для кода: чтение исходного кода и мысленное моделирование его выполнения требует когнитивных усилий и подвержено ошибкам, особенно для длинных программ или сложных UI-приложений.
Рассмотрим этот сценарий: вы просите две AI-модели создать адаптивный веб-сайт галереи фотографий. Обе генерируют код, который выглядит синтаксически правильным. Но какой из них действительно лучше? Без запуска кода почти невозможно сказать. Один может создать красивую, функциональную сетку, а другой может иметь незаметные ошибки или плохое оформление, которые становятся видны только при рендеринге в браузере.
Это наблюдение привело нас к ключевому выводу: обратная связь от выполнения необходима для надежной оценки качества кода человеком. Именно это и предоставляет BigCodeArena.
Платформа BigCodeArena
BigCodeArena расширяет фреймворк Chatbot Arena мощными функциями, специально разработанными для оценки кода:
Реальное выполнение в реальном времени
Каждый фрагмент кода, сгенерированный моделями, автоматически выполняется в изолированных песочницах. Будь то Python-скрипт, React веб-приложение, PyGame игра или C++ алгоритм — вы можете увидеть реальный вывод, а не только исходный код.
Поддержка множества языков и фреймворков
В настоящее время поддерживается 10 языков (Python, JavaScript, TypeScript, HTML, C, C++, Java, Go, Rust и Markdown) и 8 сред выполнения:
- Веб-фреймворки: React, Vue, Core Web (vanilla HTML/CSS/JS)
- Python-фреймворки: Streamlit, Gradio, PyGame
- Диаграммы: Mermaid
- Интерпретаторы общего назначения: Python и JavaScript, плюс раннеры для компилируемых языков
Интерактивное тестирование
В отличие от статического сравнения кода, вы можете фактически взаимодействовать с сгенерированными приложениями:
- Нажимать кнопки и тестировать UI-элементы в веб-приложениях
- Играть в игры, созданные моделями
- Редактировать код и перезапускать его для тестирования модификаций
- Просматривать визуальные выводы вроде графиков, диаграмм и схем
Многотуровые беседы
Настоящее программирование не заканчивается одним действием. BigCodeArena поддерживает многотуровые взаимодействия, позволяя уточнять требования, добавлять функции или запрашивать исправления ошибок — точно так же, как при работе с реальным помощником по программированию.
Наконец-то кто-то додумался оценивать код не по красоте синтаксиса, а по реальной работоспособности. Это все равно что судить повара по вкусу блюда, а не по красоте рецепта. Интересно, сколько «идеальных» моделей генерации кода окажутся бесполезными в реальных условиях, когда их творения начнут падать с ошибками выполнения или выдавать неожиданные результаты.
Что мы узнали: 5 месяцев общественной оценки
С момента запуска в феврале 2025 года BigCodeArena собрала более 14 000 бесед от более чем 500 уникальных пользователей с 4700+ качественных предпочтений голосов, сравнивающих 10 передовых LLM.
Темы программирования в реальных условиях
Наши пользователи исследовали удивительно разнообразные сценарии кодирования:
- Веб-дизайн (36%): Создание адаптивных веб-сайтов, интерактивных дашбордов и веб-приложений
- Решение проблем (23%): Алгоритмы, структуры данных и вычислительные задачи
- Разработка игр (16%): Создание интерактивных игр с физикой, обнаружением столкновений и графикой
- Научные вычисления (14%): Анализ данных, визуализация и численное моделирование
- Творческое программирование (8%): Художественные визуализации, генеративное искусство и экспериментальные интерфейсы
- Создание диаграмм (3%): Блок-схемы, системные архитектуры и визуализации данных
Популярность языков и фреймворков
Python доминирует с более чем 4000 бесед, за ним следуют JavaScript/TypeScript (3359), HTML (1601) и C++ (642). Среди фреймворков прямые интерпретаторы Python лидируют по использованию (6000 сессий), с React (2729), Core Web (1574), Streamlit (1254) и PyGame (1087) также показывая активное использование.
Паттерны взаимодействия пользователей
Большинство взаимодействий сосредоточены и эффективны: 76% бесед состоят всего из 2 туров (один запрос, один ответ), со средней длиной беседы 4.12 сообщения. Однако платформа поддерживает расширенные многотуровые сессии отладки, когда это необходимо, с некоторыми беседами, превышающими 10 туров, когда пользователи дорабатывают сложные приложения.
Рейтинги моделей от голосов сообщества
Из наших 14K бесед мы отфильтровали качественные попарные сравнения: беседы с как минимум двумя турами и фактическим выполнением кода. Это дало 4731 образец голосования, с каждой оцениваемой моделью, получившей как минимум 700 голосов. Мы агрегируем эти голоса в рейтинги Elo, используя модель Bradley-Terry, которая оценивает вероятность того, что одна модель побьет другую на основе прямых сравнений.
Для обеспечения надежных рейтингов мы используем 100 бутстрап-ресэмплов для построения 95% доверительных интервалов, чтобы мы могли идентифицировать статистически значимые различия в производительности между моделями.
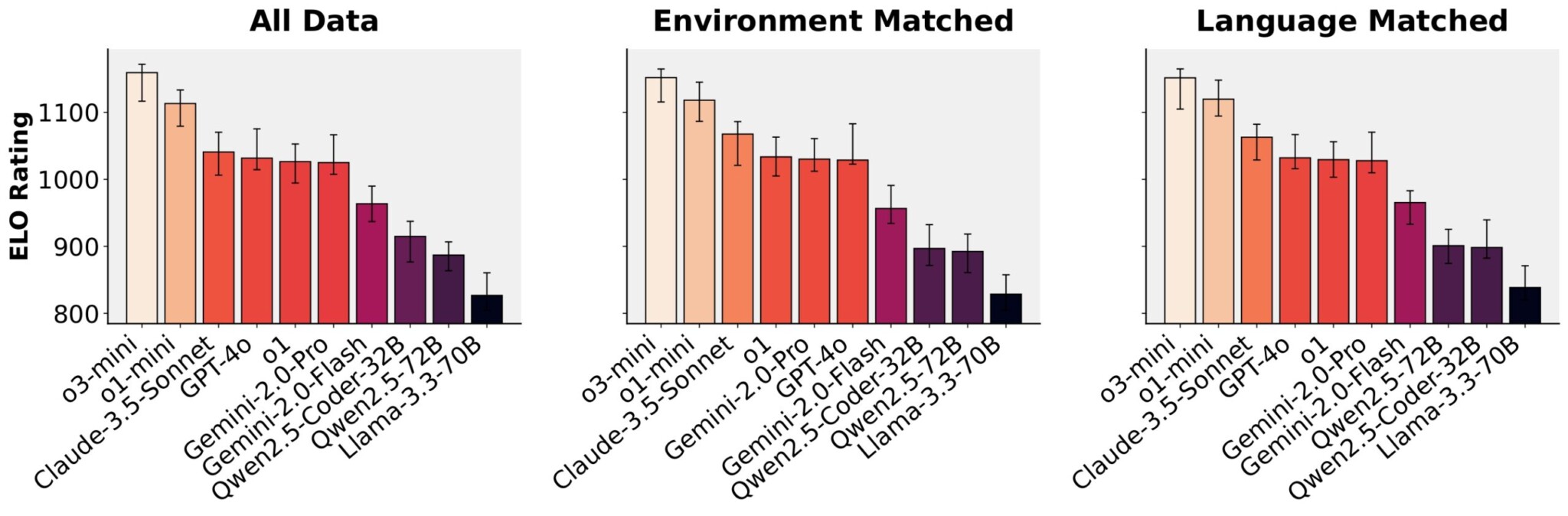
Мы оцениваем модели в трех настройках для контроля различных факторов:
- Все данные: Использует все попарные сравнения независимо от среды выполнения или языка программирования
- Совпадение среды: Сравнивает модели только когда обе тестировались в одинаковой среде выполнения
- Совпадение языка: Сравнивает модели только когда обе генерировали код на одном языке программирования
Платформа доступна на GitHub, HF Collection и с документацией.
По материалам Hugging Face.



